MIT has appointed McGovern faculty members Sven Dorkenwald and Josh McDermott to named professorships that will provide additional support for their “outstanding research and educational careers.” Named professorships at MIT are prestigious endowed faculty chairs that provide crucial financial support for both junior faculty and senior scholars, enabling them to pursue bold research and global challenges.
Dorkenwald, who recently joined MIT as an assistant professor of brain and cognitive sciences and an investigator at the McGovern Institute, has been selected to hold the Silverman (1968) Family Career Development Professorship for a three-year term beginning July 1, 2026. A trailblazer in the field of computational neuroscience, Dorkenwald reconstructs maps of neuronal circuits to investigate how they support complex computations. He is recognized for his leadership in connectomics—an emerging discipline focused on reconstructing and analyzing neural circuitry at unprecedented scale and detail. Jeffrey Silverman ’68 is a life member emeritusof the MIT Corporation. His generousgift to the institute empowers early career professors to pursue high-risk research.
McDermott, a professor of brain and cognitive sciences and an associate investigator at the McGovern Institute, has been selected to hold the Uncas (1923) and Helen Whitaker Professorship for a five-year renewable term beginning July 1, 2026. McDermott’s research operates at the intersection of psychology, neuroscience, and engineering to study how people hear and interpret sound. Groundbreaking discoveries from the McDermott lab are informing new treatments for hearing loss, and paving the way for machine systems that emulate the human ability to recognize and interpret sound. The Uncas (1923) and Helen Whitaker Professorship chair was established in 1980 through a gift from the late Helen Whitaker, the first woman elected to life membership of the MIT Corporation. It is designed to support distinguished faculty whose work spans multiple disciplines to solve complex, real-world problems.
Schizophrenia, a complex and variable psychiatric disorder, changes people’s perceptions of reality. People with schizophrenia may hear, see, or sense things that aren’t there, and they often hold firm to mistaken ideas about the world despite strong evidence to the contrary. As if these changes aren’t disruptive enough, they are usually accompanied by cognitive difficulties and disorganized thinking.
Scientists at the McGovern Institute’s Poitras Center for Psychiatric Disorders Research are looking for clues into the origins of the disorder and its symptoms so they can help guide the development of new treatments. Encouragingly, they are beginning to uncover the brain changes that reshape reality for people with schizophrenia.
Genetic clues
Researchers who want to study the root causes of a disease often turn to genetics for clues—and the genetics of schizophrenia are complicated. Hundreds of different genes seem to shape people’s risk of developing the disorder, most of which nudge risk only slightly. For most people, it seems to be the cumulative effect of these genes and how they intersect with other risk factors, like stress and prenatal complications, that determine who develops schizophrenia and who does not.
Gene variants that substantially impact the risk of schizophrenia are expected to reveal more about the underlying biology of the disorder than genes whose individual impact is minor. But these variants are rare, and it took a massive study to find them. In 2022, scientists at the Broad Institute’s Stanley Center for Psychiatric Research reported that after analyzing the DNA of more than 24,000 people with schizophrenia, they had identified mutations in 10 genes that dramatically increased the risk of the disorder.
“I think this is exciting, because for the first time, you can actually have an animal model based onhuman genetics findings,” says McGovern Institute and Stanley Center Investigator Guoping Feng. “You can put these mutations in animal models to try to understand how this mutation affects brain development, circuit formation, circuit function, and behavior.” Feng is also the James W. (1963) and Patricia T. Poitras Professor of Brain and Cognitive Sciences at MIT.
Guoping Feng (right) and his postdoctoral researcher Tinting Zhou (left) examine a mouse brain carrying a genetic mutation associated with schizophrenia. Photo: Steph Stevens
In work supported by the Poitras Center, the Stelling Family Research Fund, and the Yang Tan Collective at MIT, Feng’s lab has engineered three strains of mice that carry ultra-rare schizophrenia-associated mutations. Their first significant findings come from mice with a mutation in a gene called Grin2a. People who inherit a dysfunctional Grin2a gene, which neurons need to detect and respond to a signaling molecule called NMDA, are 20 times more likely to develop schizophrenia than people in whom Grin2a is intact.
Tingting Zhou, a postdoctoral researcher in Feng’s lab, says the team had to think carefully about how to assess mice for schizophrenia-like symptoms. You can’t ask mice about hallucinations or delusions. Instead, Zhou designed an experiment that tested how well mice use new information to update their beliefs about the world—a process that is thought to be impaired in people who experience delusions.
To illustrate how failure to update beliefs can skew someone’s ideas about reality, Zhou describes a situation in which a person watches a stranger reach for something in their pocket, fearing that person intends to harm them. Then, the stranger’s hand emerges with a lollipop. The new information should alleviate concern—but a person with schizophrenia might hold on to their original belief, convinced the lollipop-holding stranger is a threat.
In Zhou’s experiments testing animals’ belief-updating abilities, mice had to keep up with changing information to earn as many treats as possible. Those with the Grin2a mutation were slow to adapt when experimenters adjusted the relative values of their choices. “Once the animal learns something, it’s very hard for them to update the information,” Zhou explains.
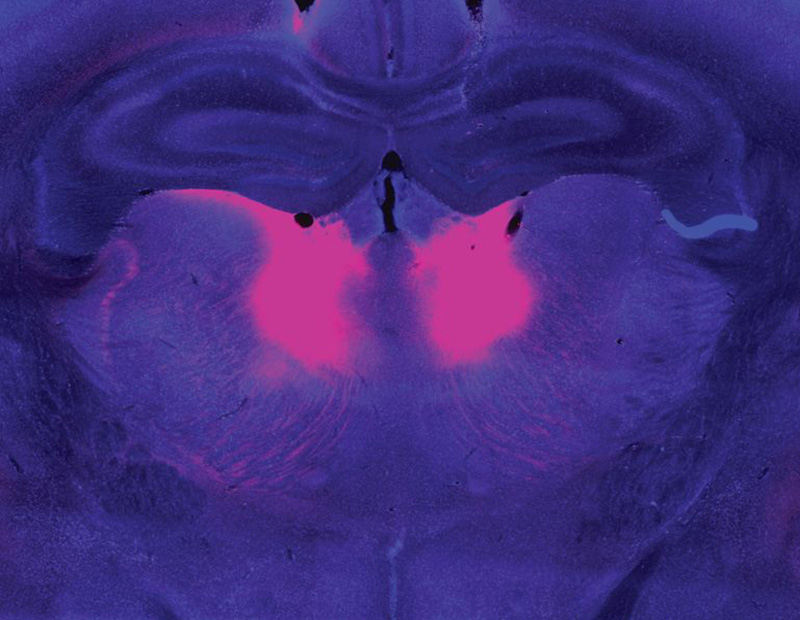
Zhou and Feng linked this behavioral difference to abnormally low activity in a part of the brain called the mediodorsal thalamus. The mediodorsal thalamus acts like a switchboard in the brain, routing and coordinating information between different parts of the cortex to support thinking, decision-making, and flexible behavior. Studies with patients have implicated this region in schizophrenia as well, showing that it has fewer cells and is less active in people with the disorder than those without.
The mediodorsal thalamus (pink) is less active in people with schizophrenia and mouse models of the disease. Image: Guoping Feng, Tingting Zhou
Feng’s lab and others are now looking for belief-updating deficits in other genetic models of schizophrenia. “The goal is to look at whether this is a converging mechanism…then you can start to look at what other [brain] regions are involved,” he says.
In mice with Grin2a mutations, the researchers were able to restore normal belief updating by activating neurons in the mediodorsal thalamus, offering hope that manipulating the same circuitry might benefit patients. “It will not be easy,” Feng says, “but at least you have something you can work on. Previously, it was just very hard to imagine how to develop a new therapeutic for schizophrenia.”
Internal noise
It’s not just the genes associated with schizophrenia that differ across affected individuals. The symptoms of the disorder vary, too. People experience some combination of delusions, hallucinations, disorganized speech, and cognitive problems—but none of these are experienced by everyone with the disorder. This heterogeneity complicates the diagnosis, treatment, and study of schizophrenia. For this reason, some researchers are focusing their efforts on understanding its individual symptoms.
Evelina Fedorenko, a McGovern Investigator and associate professor of brain and cognitive sciences, specializes in understanding how the brain processes speech and language. But recently, her group has teamed up with physician-researcher Ann Shinn at McLean Hospital to begin exploring why some people hear voices when no one is speaking.
About three out of four people with schizophrenia experience auditory hallucinations, which most commonly involve voices.
These hallucinations can be distressing, sometimes involving threatening language or commands to cause harm. Some people with mood disorders or post-traumatic stress disorder also hear them.
Tamar Regev was the 2022–2024 Poitras Center Postdoctoral Fellow in Evelina Fedorenko’s lab. Photo: Steph Stevens
To investigate, Tamar Regev, a research scientist in the Fedorenko lab, asked people who experience auditory hallucinations to listen to different kinds of sounds inside an MRI scanner, then compared how their brains responded versus the brains of people without auditory hallucinations. Her study included participants with schizophrenia and bipolar disorder, both with and without a history of auditory hallucinations, as well as healthy controls.
Inside the scanner, participants listened to three kinds of audio: spoken language, gibberish, and gibberish so scrambled that it barely resembled speech. Regev analyzed how these sounds impacted activity in areas the brain uses to process auditory input at different levels: a part of the auditory cortex that is sensitive to all sounds; a higher-level region within the auditory cortex that usually responds to anything that sounds like speech, even if its content is unclear; and the brain’s language-processing network, which is called on to understand the content of speech, as well as written or signed communications.
Regev found that in people with hallucinations, the part of the brain that usually responds only to language responded to meaningless speech as well. “In this pathway from auditory to speech to language processing, the stimuli that should be filtered out somewhere on the way are now passing to higher stations,” she explains. While auditory hallucinations don’t require external sounds, Fedorenko and Regev propose that the brain’s language areas might be similarly activated by “internal noise” in auditory circuits.
Scrambled language
In people who experience auditory hallucinations, the brain’s language regions respond to sounds that aren’t language–including scrambled meaningless gibberish. Below is a sample gibberish clip used in Fedorenko’s study.
Early identification
McGovern scientists have also used brain imaging to investigate what happens in the brain before people develop clear symptoms of schizophrenia. The disorder is usually diagnosed in adolescence or young adulthood, when patients exhibit the first signs of psychosis—but its origins in the brain likely take root years before that.
“One of the things we’re super interested in is, can you identify people at risk early on, before they have a big problem,” says McGovern Investigator John Gabrieli, whose work is also supported by the Poitras Center and the Stelling Family Research Fund. That might give clinicians an opportunity to intervene and lessen or prevent the disorder’s most devastating effects, he says.
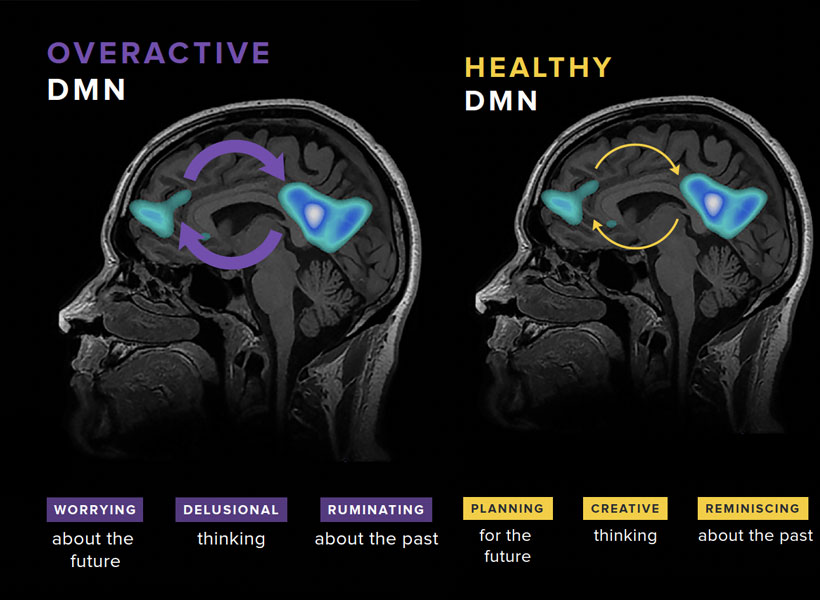
Gabrieli and his colleagues have studied the brains of children who, because they have a parent or sibling with schizophrenia, have an elevated risk of developing the disorder themselves. They found that a system called the default mode network (DMN), which is overactive in adults with schizophrenia, is already working overtime when children in this high-risk group are seven- to 12-years-old.
Gabrieli explains that the DMN is active when people are not actively engaged in an activity or thinking about the external world. “It turns on when you think about your family, your values, your hopes for the future, or important events of your life. It’s almost like a system of who /you are,” he says. Hallucinations and delusions experienced by people with schizophrenia may be associated with overactivity in this network.
The default mode network (DMN) is a large-scale brain network that is active when a person is not focused on the outside world and the brain is at wakeful rest. The DMN is often over-engaged in adolescents with depression and anxiety, as well as teens at risk for these and other disorders like schizophrenia (left). DMN activation and connectivity can be “tuned” to a healthier state through the practice of mindfulness (right).
“They’re kind of living in their internal world of beliefs, as opposed to the reality that most of us occupy,” Gabrieli explains.
He and his colleagues think overactivity in the DMN might make people vulnerable to schizophrenia—and their data show this atypical activity can be detected many years before the core symptoms of schizophrenia appear. With further validation, children with hyperactivity of the DMN might be candidates for early intervention.
With new and better interventions, the ability to identify people who may be on a path toward schizophrenia will be even more impactful—underscoring the need for continued research on multiple fronts. A recent gift of $8 million to the Poitras Center from Patricia and James Poitras is helping accelerate this work in labs at the McGovern Institute and beyond.
When patients undergo general anesthesia, doctors can choose among several drugs. Although each of these drugs acts on neurons in different ways, they all lead to the same result: a disruption of the brain’s balance between stability and excitability, according to a new MIT study.
This disruption causes neural activity to become increasingly unstable, until the brain loses consciousness, the researchers found. The discovery of this common mechanism could make it easier to develop new technologies for monitoring patients while they are undergoing anesthesia.
“What’s exciting about that is the possibility of a universal anesthesia-delivery system that can measure this one signal and tell how unconscious you are, regardless of which drugs they’re using in the operating room,” says Earl Miller, the Picower Professor of Neuroscience and a member of MIT’s Picower Institute for Learning and Memory.
Miller, Edward Hood Taplin Professor of Medical Engineering and Computational Neuroscience Emery Brown, and their colleagues are now working on an automated control system for delivery of anesthesia drugs, which would measure the brain’s stability using EEG and then automatically adjust the drug dose. This could help doctors ensure that patients stay unconscious throughout surgery without becoming too deeply unconscious, which can have negative side effects following the procedure.
Miller and Ila Fiete, a professor of brain and cognitive sciences, the director of the K. Lisa Yang Integrative Computational Neuroscience Center (ICoN), and a member of MIT’s McGovern Institute for Brain Research, are the senior authors of the new study, which appears today in Cell Reports. MIT graduate student Adam Eisen is the paper’s lead author.
Destabilizing the brain
Exactly how anesthesia drugs cause the brain to lose consciousness has been a longstanding question in neuroscience. In 2024, a study from Miller’s and Fiete’s labs suggested that for propofol, the answer is that anesthesia works by disrupting the balance between stability and excitability in the brain.
When someone is awake, their brain is able to maintain this delicate balance, responding to sensory information or other input and then returning to a stable baseline.
“The nervous system has to operate on a knife’s edge in this narrow range of excitability,” Miller says. “It has to be excitable enough so different parts can influence one another, but if it gets too excited it goes off into chaotic activity.”
In that 2024 study, the researchers found that propofol knocks the brain out of this state, known as “dynamic stability.” As doses of the drug increased, the brain took longer and longer to return to its baseline state after responding to new input. This effect became increasingly pronounced until consciousness was lost.
For that study, the researchers devised a computational model that analyzes neural activity recorded from the brain. This technique allowed them to determine how the brain responds to perturbations such as an auditory tone or other sensory input, and how long it takes to return to its baseline stability.
In their new study, the researchers used the same technique to measure how the brain responds to not only propofol but two additional anesthesia drugs — ketamine and dexmedetomidine. Animals were given one of the three drugs while their brain activity was analyzed, including their response to auditory tones.
This study showed that the same destabilization induced by propofol also appears during administration of the other two drugs. This “universal signature” appears even though the three drugs have different molecular mechanisms: propofol binds to GABA receptors, inhibiting neurons that have those receptors; dexmedetomidine blocks the release of norepinephrine; and ketamine blocks NMDA receptors, suppressing neurons with those receptors.
Each of these pathways, the researchers hypothesize, affect the brain’s balance of stability and excitability in different ways, and each leads to an overall destabilization of this balance.
“All three of these drugs appear to do the exact same thing,” Miller says. “In fact, you could look at the destabilization measure we use and you can’t tell which drug is being applied.”
The researchers now plan to further investigate how each of these drugs may give rise to the same patterns of brain destabilization.
“The molecular mechanisms of ketamine and dexmedetomidine are a bit more involved than propofol mechanisms,” Eisen says. “A future direction is to do a meaningful model of what the biophysical effects of those are and see how that could lead to destabilization.”
Monitoring anesthesia
Now that the researchers have shown that three different anesthesia drugs produce similar destabilization patters in the brain, they believe that measuring those patterns could offer a valuable way to monitor patients during anesthesia. While anesthesia is overall a very safe procedure, it does carry some risks, especially for very young children and for people over 65.
For adults suffering from dementia, anesthesia can make the condition worse, and it can also exacerbate neuropsychiatric disorders such as depression. These risks are higher if patients go into a deeper state of unconsciousness known as burst suppression.
To help reduce those risks, Miller and Brown, who is also an anesthesiologist at MGH, are developing a prototype device that can measure patients’ EEG readings while under anesthesia and adjust their dose accordingly. Currently, doctors monitor patients’ heart rate, blood pressure, and other vital signs during surgery, but these don’t give as accurate a reading of how deeply the patient is unconscious.
“If you can limit people’s exposure to anesthesia, if you give just enough and no more, you can reduce risks across the board,” Miller says.
Working with researchers at Brown University, the MIT team is now planning to run a small clinical trial of their monitoring device with patients undergoing surgery.
The research was funded by the U.S. Office of Naval Research, the National Institute of Mental Health, the Simons Center for the Social Brain, the Freedom Together Foundation, the Picower Institute, the National Science Foundation Computer and Information Science and Engineering Directorate, the Simons Collaboration on the Global Brain, the McGovern Institute, and the National Institutes of Health.
MIT neuroscientists have figured out how the brain is able to focus on a single voice among a cacophony of many voices, shedding light on a longstanding neuroscientific phenomenon known as the cocktail party problem.
This attentional focus becomes necessary when you’re in any crowded environment, such as a cocktail party, with many conversations going on at once. Somehow, your brain is able to follow the voice of the person you’re talking to, despite all the other voices that you’re hearing in the background.
Using a computational model of the auditory system, the MIT team found that amplifying the activity of the neural processing units that respond to features of a target voice, such as its pitch, allows that voice to be boosted to the forefront of attention.
“That simple motif is enough to cause much of the phenotype of human auditory attention to emerge, and the model ends up reproducing a very wide range of human attentional behaviors for sound,” says Josh McDermott, a professor of brain and cognitive sciences at MIT, a member of MIT’s McGovern Institute for Brain Research and Center for Brains, Minds, and Machines, and the senior author of the study.
The findings are consistent with previous studies showing that when people or animals focus on a specific auditory input, neurons in the auditory cortex that respond to features of the target stimulus amplify their activity. This is the first study to show that extra boost is enough to explain how the brain solves the cocktail party problem.
Ian Griffith, a graduate student in the Harvard Program in Speech and Hearing Biosciences and Technology, who is advised by McDermott, is the lead author of the paper. MIT graduate student R. Preston Hess is also an author of the paper, which appears today in Nature Human Behavior.
Modeling attention
Neuroscientists have been studying the phenomenon of selective attention for decades. Many studies in people and animals have shown that when focusing on a particular stimulus like the sound of someone’s voice, neurons that are tuned to features of that voice — for example, high pitch — amplify their activity.
When this amplification occurs, neurons’ firing rates are scaled upward, as though multiplied by a number greater than one. It has been proposed that these “multiplicative gains” allow the brain to focus its attention on certain stimuli. Neurons that aren’t tuned to the target feature exhibit a corresponding reduction in activity.
“The responses of neurons tuned to features that are in the target of attention get scaled up,” Griffith says. “Those effects have been known for a very long time, but what’s been unclear is whether that effect is sufficient to explain what happens when you’re trying to pay attention to a voice or selectively attend to one object.”
This question has remained unanswered because computational models of perception haven’t been able to perform attentional tasks such as picking one voice out of many. Such models can readily perform auditory tasks when there is an unambiguous target sound to identify, but they haven’t been able to perform those tasks when other stimuli are competing for their attention.
“None of our models has had the ability that humans have, to be cued to a particular object or a particular sound and then to base their response on that object or that sound. That’s been a real limitation,” McDermott says.
In this study, the MIT team wanted to see if they could train models to perform those types of tasks by enabling the model to produce neuronal activity boosts like those seen in the human brain.
To do that, they began with a neural network that they and other researchers have used to model audition, and then modified the model to allow each of its stages to implement multiplicative gains. Under this architecture, the activation of processing units within the model can be boosted up or down depending on the specific features they represent, such as pitch.
To train the model, on each trial the researchers first fed it a “cue”: an audio clip of the voice that they wanted the model to pay attention to. The unit activations produced by the cue then determined the multiplicative gains that were applied when the model heard a subsequent stimulus.
“Imagine the cue is an excerpt of a voice that has a low pitch. Then, the units in the model that represent low pitch would get multiplied by a large gain, whereas the units that represent high pitch would get attenuated,” Griffith says.
Then, the model was given clips featuring a mix of voices, including the target voice, and asked to identify the second word said by the target voice. The model activations to this mixture were multiplied by the gains that resulted from the previous cue stimulus. This was expected to cause the target voice to be “amplified” within the model, but it was not clear whether this effect would be enough to yield human-like attentional behavior.
The researchers found that under a variety of conditions, the model performed very similarly to humans, and it tended to make errors similar to those that humans make. For example, like humans, it sometimes made mistakes when trying to focus on one of two male voices or one of two female voices, which are more likely to have similar pitches.
“We did experiments measuring how well people can select voices across a pretty wide range of conditions, and the model reproduces the pattern of behavior pretty well,” Griffith says.
Effects of location
Previous research has shown that in addition to pitch, spatial location is a key factor that helps people focus on a particular voice or sound. The MIT team found that the model also learned to use spatial location for attentional selection, performing better when the target voice was at a different location from distractor voices.
The researchers then used the model to discover new properties of human spatial attention. Using their computational model, the researchers were able to test all possible combinations of target locations and distractor locations, an undertaking that would be hugely time-consuming with human subjects.
“You can use the model as a way to screen large numbers of conditions to look for interesting patterns, and then once you find something interesting, you can go and do the experiment in humans,” McDermott says.
These experiments revealed that the model was much better at correctly selecting the target voice when the target and distractor were at different locations in the horizontal plane. When the sounds were instead separated in the vertical plane, this task became much more difficult. When the researchers ran a similar experiment with human subjects, they observed the same result.
“That was just one example where we were able to use the model as an engine for discovery, which I think is an exciting application for this kind of model,” McDermott says.
Another application the researchers are pursuing is using this kind of model to simulate listening through a cochlear implant. These studies, they hope, could lead to improvements in cochlear implants that could help people with such implants focus their attention more successfully in noisy environments.
The research was funded by the National Institutes of Health.
McGovern Investigator Mark Harnett. Photo: Adam Glanzman
When we learn a new skill, the brain has to decide—cell by cell—what to change. New research from MIT suggests it can do that with surprising precision, sending targeted feedback to individual neurons so each one can adjust its activity in the right direction.
The finding echoes a key idea from modern artificial intelligence. Many AI systems learn by comparing their output to a target, computing an “error” signal, and using it to fine-tune connections within the network. A longstanding question has been whether the brain also uses that kind of individualized feedback. In a study published in the February 25 issue of the journal Nature, MIT researchers report evidence that it does.
A research team led by Mark Harnett, a McGovern Institute investigator and associate professor in the Department of Brain and Cognitive Sciences at MIT, discovered these instructive signals in mice by training animals to control the activity of specific neurons using a brain-computer interface (BCI). Their approach, the researchers say, can be used to further study the relationships between artificial neural networks and real brains, in ways that are expected to both improve understanding of biological learning and enable better brain-inspired artificial intelligence.
The changing brain
Our brains are constantly changing as we interact with the world, modifying their circuitry as we learn and adapt. “We know a lot from 50 years of studies that there are many ways to change the strength of connections between neurons,” Harnett says. “What the field really lacks is a way of understanding how those changes are orchestrated to actually produce efficient learning.”
Some actions—and the neural connections that enable them—are reinforced with the release of neuromodulators like dopamine or norepinephrine in the brain. But those signals are broadcast to large groups of neurons, without discriminating between cells’ individual contributions to a failure or a success. “Reinforcement learning via neuromodulators works, but it’s inefficient, because all the neurons and all the synapses basically get only one signal,” Harnett says.
Machine learning uses an alternative, and extremely powerful, way to learn from mistakes. Using a method called backpropagation, artificial neural networks compute an error signal and use it to adjust their individual connections. They do this over and over, learning from experience how to fine-tune their networks for success. “It works really well and it’s computationally very effective,” Harnett says.
It seemed likely that brains might use similar error signals for learning. But neuroscientists were skeptical that brains would have the precision to send tailored signals to individual neurons due to the constraints imposed by using living cells and circuits instead of software and equations. A major problem for testing this idea was how to find the signals that provide personalized instructions to neurons, which are called vectorized instructive signals. The challenge, explains Valerio Francioni, first author of the Nature paper and a former postdoctoral researcher in Harnett’s lab, is that scientists don’t know how individual neurons contribute to specific behaviors.
“If I was recording your brain activity while you were learning to play piano,” Francioni explains, “I would learn that there is a correlation between the changes happening in your brain and you learning piano. But if you asked me to make you a better piano player by manipulating your brain activity, I would not be able to do that, because we don’t know how the activity of individual neurons map to that ultimate performance.”
Without knowing which neurons need to become more active and which ones should be reined in, it is impossible to look for signals directing those changes.
Brain-computer interface
To get around this problem, Harnett’s team developed a brain-computer interface task to directly link neural activity and reward outcome – akin to linking the keys of the piano directly to the activity of single neurons. To succeed at the task, certain neurons needed to increase their activity, whereas others were required to decrease their activity.
They set up a BCI to directly link activity in those neurons—just eight to ten of the millions of neurons in a mouse’s brain—to a visual readout, providing sensory feedback to the mice about their performance. Success was accompanied by delivery of a sugary reward.
“Now if you ask me, ‘How does the mouse get more rewards? Which neuron do you have to activate and which neuron do you have to inhibit?’ I know exactly what the answer to that question is,” says Francioni, whose work was supported by a Y. Eva Tan Fellowship from the Yang Tan Collective at MIT.
The scientists didn’t know the exact function of the particular neurons they linked to the BCI, but the cells were active enough that mice received occasional rewards whenever the signals happened to be right. Within a week, mice learned to switch on the right neurons while leaving the other set of neurons inactive, earning themselves more rewards.
Francioni monitored the target neurons daily during this learning process using a powerful microscope to visualize fluorescent indicators of neural activity. He zeroed in on the neurons’ branching dendrites, where the appropriate feedback signals have long been suspected to arrive. At the same time, he tracked activity in the parent cell bodies of those neurons. The team used these data to examine the relationship between signals received at a neuron’s dendrites and its activity, as well as how these changed when mice were rewarded for activating the right neurons or when they failed at their task.
Vectorized neural signals
They concluded that the two groups of neurons whose activity controlled the BCI in opposite ways, also received opposing error signals at their dendrites as the mice learned. Some were told to ramp up their activity during the task, while others were instructed to dial it down. What’s more, when the team manipulated the dendrites to inhibit these instructive signals, mice failed to learn the task. “This is the first biological evidence that vectorized [neuron-specific] signal-based instructive learning is taking place in the cortex,” Harnett says.
The discovery of vectorized signals in the brain—and the team’s ability to find them—should promote more back and forth between neuroscientists and machine learning researchers, says postdoctoral researcher Vincent Tang. “It provides further incentive for the machine learning community to keep developing models and proposing new hypotheses along this direction,” he says. “Then we can come back and test them.”
The researchers say they are just as excited about applying their approach to future experiments as they are about their current discovery.
“Machine learning offers a robust, mathematically tractable way to really study learning. The fact that we can now translate at least some of this directly into the brain is very powerful,” Francioni says.
Harnett says the approach opens new opportunities to investigate possible parallels between the brain and machine learning. “Now we can go after figuring out, how does cortex learn? How do other brain regions learn? How similar or how different is it to this particular algorithm? Can we figure out how to build better, more brain-inspired models from what we learn from the biology?” he says. “This feels like a really big new beginning.”
Experience is a powerful teacher—and not every experience has to be our own to help us understand the world. What happens to others is instructive, too. That’s true for humans as well as for other social animals. New research from scientists at the McGovern Institute shows what happens in the brains of monkeys as they integrate their observations of others with knowledge gleaned from their own experience.
“The study shows how you use observation to update your assumptions about the world,” explains McGovern Institute Investigator Mehrdad Jazayeri, who led the research. His team’s findings, published in the January 7 issue of the journal Nature, also help explain why we tend to weigh information gleaned from observation and direct experience differently when we make decisions. Jazayeri is also a professor of brain and cognitive sciences at MIT and an investigator at the Howard Hughes Medical Institute.
“As humans, we do a large part of our learning through observing other people’s experiences and what they go through and what decisions they make,” says Setayesh Radkani, a graduate student in Jazayeri’s lab. For example, she says, if you get sick after eating out, you might wonder if the food at the restaurant was to blame. As you consider whether it’s safe to return, you’ll likely take into account whether the friends you’d dined with got sick too. Your experiences as well as those of your friends will inform your understanding of what happened.
The research team wanted to know how this works: When we make decisions that draw on both direct experience and observation, how does the brain combine the two kinds of evidence? Are the two kinds of information handled differently?
Social experiment
It is hard to tease out the factors that influence social learning. “When you’re trying to compare experiential learning versus observational learning, there are a ton of things that can be different,” Radkani says. For example, people may draw different conclusions about someone else’s experiences than their own, because they know less about that person’s motivations and beliefs. Factors like social status, individual differences, and emotional states can further complicate these situations and be hard to control for, even in a lab.
To create a carefully controlled scenario in which they could focus on how observation changes our understanding of the world, Radkani and postdoctoral fellow Michael Yoo devised a computer game that would allow two players to learn from one another through their experiences. They taught this game to both humans and monkeys.
Their approach, Jazayeri says, goes far beyond the kinds of tasks that are typically studied in a neuroscience lab. “I think it might be one of the most sophisticated tasks monkeys have been trained to perform in a lab,” he says.
Both monkeys and humans played the game in pairs. The object was to collect enough tokens to earn a reward. Players could choose to enter either of two virtual arenas to play—but in one of the two arenas, tokens had no value. In that arena, no matter how many tokens a player collected, they could not win. Players were not told which arena was which, and the winnable and unwinnable arenas sometimes swapped without warning.
Only one individual played at a time, but regardless of who was playing, both individuals watched all of the games. So as either player collected tokens and either did or did not receive a reward, both the player and the observer got the same information. They could use that information to decide which arena to choose in their next round.
Experience outweighs observation
Humans and monkeys have sophisticated social intelligence and both clearly took their partners’ experiences into account as they played the game. But the researchers found that the outcomes of a player’s own games had a stronger influence on each individual’s choice of arena than the outcomes of their partner’s games. “They seem to learn less efficiently from observation, suggesting they tend to devalue the observational evidence,” Radkani says. That distinction was reflected in the patterns of neural activity that the team detected in the brains of the monkeys.
Postdoctoral fellow Ruidong Chen and research assistant Neelima Valluru recorded signals from a part of the brain’s frontal lobe called the anterior cingulate cortex (ACC) as the monkeys played the game. The ACC is known to be involved in social processing. It also integrates information gained through multiple experiences, and seems to use this to update an animal’s beliefs about the world. Prior to the Jazayeri lab’s experiments, this integrative function had only been linked to animals’ direct experiences—not their observations of others.
Consistent with earlier studies, neurons in the ACC changed their activity patterns both when the monkeys played the game and when they watched their partner take a turn. But these signals were complex and variable, making it hard to discern the underlying logic. To tackle this challenge, Chen recorded neural activity from large groups of neurons in both animals across dozens of experiments. “We also had to devise new analysis methods to crack the code and tease out the logic of the computation,” Chen says.
One of the researchers’ central questions was how information about self and other makes its way to the ACC. The team reasoned that there were two possibilities: either the ACC receives a single input on each trial specifying who is acting, or it receives separate input streams for self and other. To test these alternatives, they built artificial neural network models organized both ways and analyzed how well each model matched their neural data. The results suggested that the ACC receives two distinct inputs, one reflecting evidence acquired through direct experience and one reflecting evidence acquired through observation.
The team also found a tantalizing clue about why the brain tends to trust firsthand experiences more than observations. Their analysis showed that the integration process in the ACC was biased toward direct experience. As a result, both humans and monkeys cared more about their own experiences than the experiences of their partner.
Jazayeri says the study paves the way to deeper investigations of how the brain drives social behavior. Now that his team has examined one of the most fundamental features of social learning, they plan to add additional nuance to their studies, potentially exploring how different abilities or the social relationships between animals influence learning.
“Under the broad umbrella of social cognition, this is like step zero,” he says. “But it’s a really important step, because it begins to provide a basis for understanding how the brain represents and uses social information in shaping the mind.”
This research was supported in part by the Yang Tan Collective at MIT.
The synaptic connectivity of neurons, their connectome, is fundamental to how networks of neurons function. Sven Dorkenwald develops computational and collaborative tools to map, analyze, and interpret synapse-resolution connectomes. His work has led to large connectomic reconstructions of the fruit fly brain and parts of mammalian brains. He uses these connectomes to investigate how neuronal circuits are organized and how their structure supports complex computations.
Biography
Dorkenwald joined the faculty of MIT in 2026 as an assistant professor in the Department of Brain and Cognitive Sciences and an investigator at the McGovern Institute. He earned a BS in physics and an MS in computer engineering from the University of Heidelberg, followed by a PhD in computer science and neuroscience at Princeton University in 2023 under the mentorship of Sebastian Seung and Mala Murthy. Dorkenwald completed his postdoctoral training as a Shanahan Research Fellow at the Allen Institute and the University of Washington, while serving as a Visiting Faculty Researcher at Google Research.
Honors and Awards
2026 – Searle Scholar, Kinship Foundation
2025 – STAT Wunderkind, STAT News
2024 – Larry Katz Memorial Lecture, Cold Spring Harbor Meeting on Neuronal Circuits
Large language models (LLMs) like ChatGPT can write an essay or plan a menu almost instantly. But until recently, it was also easy to stump them. The models, which rely on language patterns to respond to users’ queries, often failed at math problems and were not good at complex reasoning. Suddenly, however, they’ve gotten a lot better at these things.
A new generation of LLMs known as reasoning models are being trained to solve complex problems. Like humans, they need some time to think through problems like these—and remarkably, scientists at MIT’s McGovern Institute have found that the kinds of problems that require the most processing from reasoning models are the very same problems that people need take their time with. In other words, they report in the November 18 issue of the journal PNAS, the “cost of thinking” for a reasoning model is similar to the cost of thinking for a human.
The researchers, who were led by McGovern Institute Investigator Evelina Fedorenko, conclude that in at least one important way, reasoning models have a human-like approach to thinking. That, they note, is not by design. “People who build these models don’t care if they do it like humans. They just want a system that will robustly perform under all sorts of conditions and produce correct responses,” Fedorenko says.
“The fact that there’s some convergence is really quite striking.” — Evelina Fedorenko
Reasoning models
Like many forms of artificial intelligence, the new reasoning models are artificial neural networks: computational tools that learn how to process information when they are given data and a problem to solve. Artificial neural networks have been very successful at many of the tasks that the brain’s own neural networks do well—and in some cases, neuroscientists have discovered that those that perform best do share certain aspects of information processing in the brain. Still, some scientists argued that artificial intelligence was not ready to take on more sophisticated aspects of human intelligence.
“Up until recently, I was among the people saying, ‘these models are really good at things like perception and language, but it’s still going to be a long ways off until we have neural network models that can do reasoning,” says Fedorenko, who is also an associate professor of brain and cognitive sciences at MIT. “Then these large reasoning models emerged and they seem to do much better at a lot of these thinking tasks, like solving math problems and writing pieces of computer code.”
Computational neuroscientist Andrea Gregor de Varda is a K. Lisa Yang ICoN Center Fellow and a postdoctoral researcher in Evelina Fedorenko’s lab. Photo: Steph Stevens
Andrea Gregor de Varda, a K. Lisa Yang ICoN Center Fellow and a postdoctoral researcher in Fedorenko’s lab, explains that reasoning models work out problems step by step. “At some point, people realized that models needed to have more space to perform the actual computations that are needed to solve complex problems,” he says. “The performance started becoming way, way stronger if you let the models break down the problems into parts.”
To encourage models to work through complex problems in steps that lead to correct solutions, engineers can use reinforcement learning. During their training, the models are rewarded for correct answers and penalized for wrong ones. “The models explore the problem space themselves,” de Varda says. “The actions that lead to positive rewards are reinforced, so that they produce correct solutions more often.”
Models trained in this way are much more likely than their predecessors to arrive at the same answers a human would when they are given a reasoning task. Their stepwise problem solving does mean reasoning models can take a bit longer to find an answer than the LLMs that came before—but since they’re getting right answers where the previous models would have failed, their responses are worth the wait.
The models’ need to take some time to work through complex problems already hints at a parallel to human thinking: if you demand that a person solve a hard problem instantaneously, they’d probably fail too. De Varda wanted to examine this relationship more systematically. So he gave reasoning models and human volunteers the same set of problems, and tracked not just whether they got the answers right, but also how much time or effort it took them to get there.
Time vs. tokens
This meant measuring how long it took people to respond to each question, down to the millisecond. For the models, Varda used a different metric. It didn’t make sense to measure processing time, since this is more dependent on computer hardware than the effort the model puts into solving a problem. So instead, he tracked tokens, which are part of a model’s internal chain of thought. “They produce tokens that are not meant for the user to see and work on, but just to have some track of the internal computation that they’re doing,” de Varda explains.
“It’s as if they were talking to themselves.” — Andrea Gregor de Varda
Both humans and reasoning models were asked to solve seven different types of problems, like numeric arithmetic and intuitive reasoning. For each problem class, they were given many problems. The harder a given problem was, the longer it took people to solve it—and the longer it took people to solve a problem, the more tokens a reasoning model generated as it came to its own solution.
Likewise, the classes of problems that humans took longest to solve were the same classes of problems that required the most tokens for the models: arithmetic problems were the least demanding, whereas a group of problems called the “ARC challenge,” where pairs of colored grids represent a transformation that must be inferred and then applied to a new object, were the most costly for both people and models.
De Varda and Fedorenko say the striking match in the costs of thinking demonstrates one way in which reasoning models are thinking like humans. That doesn’t mean the models are recreating human intelligence, though. The researchers still want to know whether the models use similar representations of information to the human brain, and how those representations are transformed into solutions to problems. They’re also curious whether the models will be able to handle problems that require world knowledge that is not spelled out in the texts that are used for model training.
The researchers point out that even though reasoning models generate internal monologues as they solve problems, they are not necessarily using language to think. “If you look at the output that these models produce while reasoning, it often contains errors or some nonsensical bits, even if the model ultimately arrives at a correct answer. So the actual internal computations likely take place in an abstract, non-linguistic representation space, similar to how humans don’t use language to think,” he says.
Nidhi Seethapathi is an associate investigator at the McGovern Institute as well as the Frederick A. (1971) and Carole J. Middleton Career Development Assistant Professor in Brain and Cognitive Sciences and Electrical Engineering and Computer Science at MIT.
With every step we take, our brains are already thinking about the next one. If a bump in the terrain or a minor misstep has thrown us off balance, our stride may need to be altered to prevent a fall. Our two-legged posture makes maintaining stability particularly complex, which our brains solve in part by continually monitoring our bodies and adjusting where we place our feet.
Now, scientists at MIT’s McGovern Institute have determined that animals with very different bodies likely use a shared strategy to balance themselves when they walk.
McGovern Associate Investigator Nidhi Seethapathi and K. Lisa Yang ICoN Center Fellow Antoine De Comite found that humans, mice, and fruit flies all use an error-correction process to guide foot placement and maintain stability while walking. Their findings, published October 21, 2025, in the journal PNAS, could inform future studies exploring how the brain achieves stability during locomotion – bridging the gap between animal models and human balance.
Corrective action
Information must be integrated by the brain to keep us upright when we walk or run. Our steps must be continually adjusted according to the terrain, our desired speed, and our body’s current velocity and position in space.
“We rely on a combination of vestibular, proprioceptive, and visual information to build an estimate of our body’s state, determining if we are about to fall. Once we know the body’s state, we can decide which corrective actions to take,” explains Seethapathi, who is also the Frederick A. (1971) and Carole J. Middleton Career Development Assistant Professor in Brain and Cognitive Sciences and Electrical Engineering and Computer Science at MIT.
While humans are known to adjust where they place their feet to correct for errors, it is not known whether animals whose bodies are more stable do this, too.
Antoine DeComite is a K. Lisa Yang ICoN Postdoctoral Fellow in Nidhi Seethapathi’s lab at the McGovern Institute. Photo: Steph Stevens
To find out, Seethapathi and De Comite, who is a postdoctoral research in both Seethapathi’s and Guoping Feng’s labs, turned to locomotion data from mice, fruit flies, and humans shared by other labs, enabling an analysis across species which is otherwise challenging. Importantly, Seethapathi notes, all the animals they studied were walking in everyday natural environments, such as around a room—not on a treadmill or over unusual terrain.
Even in these ordinary circumstances, missteps and minor imbalances are common, and the team’s analysis showed that these errors predicted where all of the animals placed their feet in subsequent steps, regardless of whether they had two, four, or six legs.
By tracking the animals’ bodies and the step-by-step placement of their feet, Seethapathi and De Comite were able to find a measure of error that informs each animal’s next step. “By taking this comparative approach, we’ve forced ourselves to come up with a definition of error that generalizes across species,” Seethapathi says. “An animal moves with an expected body state for a particular speed. If it deviates from that ideal state, that deviation—at any given moment—is the error.”
“It was surprising to find similarities across these three species, which, at first sight, look very different,” says DeComite.
“The methods themselves are surprising because we now have a pipeline to analyze foot placement and locomotion stability in any legged species,” explains DeComite, “which could lead similar analyses in even more species in the future.”
The team’s data suggest that in all of the species in the study, placement of the feet is guided both by an error-correction process and the speed at which an animal is traveling. Steps tend to lengthen and feet spend less time on the ground as animals pick up their pace, while the width of each step seems to change largely to compensate for body-state errors.
Now, Seethapathi says, we can look forward to future studies to explore how the dual control systems might be generated and integrated in the brain to keep moving bodies stable.
Studying how brains help animals move stably may also guide the development of more targeted strategies to help people improve their balance and, ultimately, prevent falls.
“In elderly individuals and individuals with sensorimotor disorders , minimizing fall risk is one of the major functional targets of rehabilitation,” says Seethapathi. “A fundamental understanding of the error correction process that helps us remain stable will provide insight into why this process falls short in populations with neural deficits,” she says.
Which of those sentences are you most likely to remember a few minutes from now? If you guessed the second, you’re probably correct.
According to a new study from MIT cognitive scientists, sentences that stick in your mind longer are those that have distinctive meanings, making them stand out from sentences you’ve previously seen. They found that meaning, not any other trait, is the most important feature when it comes to memorability.
Greta Tuckute, a former graduate student in the Fedorenko lab. Photo: Caitlin Cunningham
“One might have thought that when you remember sentences, maybe it’s all about the visual features of the sentence, but we found that that was not the case. A big contribution of this paper is pinning down that it is the meaning-related space that makes sentences memorable,” says Greta Tuckute PhD ’25, who is now a research fellow at Harvard University’s Kempner Institute.
The findings support the hypothesis that sentences with distinctive meanings — like “Does olive oil work for tanning?” — are stored in brain space that is not cluttered with sentences that mean almost the same thing. Sentences with similar meanings end up densely packed together and are therefore more difficult to recognize confidently later on, the researchers believe.
“When you encode sentences that have a similar meaning, there’s feature overlap in that space. Therefore, a particular sentence you’ve encoded is not linked to a unique set of features, but rather to a whole bunch of features that may overlap with other sentences,” says Evelina Fedorenko, an MIT associate professor of brain and cognitive sciences (BCS), a member of MIT’s McGovern Institute for Brain Research, and the senior author of the study.
Tuckute and Thomas Clark, an MIT graduate student, are the lead authors of the paper, which appears in the Journal of Memory and Language. MIT graduate student Bryan Medina is also an author.
Distinctive sentences
What makes certain things more memorable than others is a longstanding question in cognitive science and neuroscience. In a 2011 study, Aude Oliva, now a senior research scientist at MIT and MIT director of the MIT-IBM Watson AI Lab, showed that not all items are created equal: Some types of images are much easier to remember than others, and people are remarkably consistent in what images they remember best.
In that study, Oliva and her colleagues found that, in general, images with people in them are the most memorable, followed by images of human-scale space and close-ups of objects. Least memorable are natural landscapes.
As a follow-up to that study, Fedorenko and Oliva, along with Ted Gibson, another faculty member in BCS, teamed up to determine if words also vary in their memorability. In a study published earlier this year, co-led by Tuckute and Kyle Mahowald, a former PhD student in BCS, the researchers found that the most memorable words are those that have the most distinctive meanings.
Words are categorized as being more distinctive if they have a single meaning, and few or no synonyms — for example, words like “pineapple” or “avalanche” which were found to be very memorable. On the other hand, words that can have multiple meanings, such as “light,” or words that have many synonyms, like “happy,” were more difficult for people to recognize accurately.
In the new study, the researchers expanded their scope to analyze the memorability of sentences. Just like words, some sentences have very distinctive meanings, while others communicate similar information in slightly different ways.
To do the study, the researchers assembled a collection of 2,500 sentences drawn from publicly available databases that compile text from novels, news articles, movie dialogues, and other sources. Each sentence that they chose contained exactly six words.
The researchers then presented a random selection of about 1,000 of these sentences to each study participant, including repeats of some sentences. Each of the 500 participants in the study was asked to press a button when they saw a sentence that they remembered seeing earlier.
The most memorable sentences — the ones where participants accurately and quickly indicated that they had seen them before — included strings such as “Homer Simpson is hungry, very hungry,” and “These mosquitoes are — well, guinea pigs.”
Those memorable sentences overlapped significantly with sentences that were determined as having distinctive meanings as estimated through the high-dimensional vector space of a large language model (LLM) known as Sentence BERT. That model is able to generate sentence-level representations of sentences, which can be used for tasks like judging meaning similarity between sentences. This model provided researchers with a distinctness score for each sentence based on its semantic similarity to other sentences.
The researchers also evaluated the sentences using a model that predicts memorability based on the average memorability of the individual words in the sentence. This model performed fairly well at predicting overall sentence memorability, but not as well as Sentence BERT. This suggests that the meaning of a sentence as a whole — above and beyond the contributions from individual words — determines how memorable it will be, the researchers say.
Noisy memories
While cognitive scientists have long hypothesized that the brain’s memory banks have a limited capacity, the findings of the new study support an alternative hypothesis that would help to explain how the brain can continue forming new memories without losing old ones.
This alternative, known as the noisy representation hypothesis, says that when the brain encodes a new memory, be it an image, a word, or a sentence, it is represented in a noisy way — that is, this representation is not identical to the stimulus, and some information is lost. For example, for an image, you may not encode the exact viewing angle at which an object is shown, and for a sentence, you may not remember the exact construction used.
Under this theory, a new sentence would be encoded in a similar part of the memory space as sentences that carry a similar meanings, whether they were encountered recently or sometime across a lifetime of language experience. This jumbling of similar meanings together increases the amount of noise and can make it much harder, later on, to remember the exact sentence you have seen before.
“The representation is gradually going to accumulate some noise. As a result, when you see an image or a sentence for a second time, your accuracy at judging whether you’ve seen it before will be affected, and it’ll be less than 100 percent in most cases,” Clark says.
However, if a sentence has a unique meaning that is encoded in a less densely crowded space, it will be easier to pick out later on.
“Your memory may still be noisy, but your ability to make judgments based on the representations is less affected by that noise because the representation is so distinctive to begin with,” Clark says.
The researchers now plan to study whether other features of sentences, such as more vivid and descriptive language, might also contribute to making them more memorable, and how the language system may interact with the hippocampal memory structures during the encoding and retrieval of memories.
The research was funded, in part, by the National Institutes of Health, the McGovern Institute, the Department of Brain and Cognitive Sciences, the Simons Center for the Social Brain, and the MIT Quest Initiative for Intelligence.