This story also appears in our Spring 2026 BrainScan newsletter.
***
Schizophrenia, a complex and variable psychiatric disorder, changes people’s perceptions of reality. People with schizophrenia may hear, see, or sense things that aren’t there, and they often hold firm to mistaken ideas about the world despite strong evidence to the contrary. As if these changes aren’t disruptive enough, they are usually accompanied by cognitive difficulties and disorganized thinking.
Scientists at the McGovern Institute’s Poitras Center for Psychiatric Disorders Research are looking for clues into the origins of the disorder and its symptoms so they can help guide the development of new treatments. Encouragingly, they are beginning to uncover the brain changes that reshape reality for people with schizophrenia.
Genetic clues
Researchers who want to study the root causes of a disease often turn to genetics for clues—and the genetics of schizophrenia are complicated. Hundreds of different genes seem to shape people’s risk of developing the disorder, most of which nudge risk only slightly. For most people, it seems to be the cumulative effect of these genes and how they intersect with other risk factors, like stress and prenatal complications, that determine who develops schizophrenia and who does not.
Gene variants that substantially impact the risk of schizophrenia are expected to reveal more about the underlying biology of the disorder than genes whose individual impact is minor. But these variants are rare, and it took a massive study to find them. In 2022, scientists at the Broad Institute’s Stanley Center for Psychiatric Research reported that after analyzing the DNA of more than 24,000 people with schizophrenia, they had identified mutations in 10 genes that dramatically increased the risk of the disorder.
“I think this is exciting, because for the first time, you can actually have an animal model based onhuman genetics findings,” says McGovern Institute and Stanley Center Investigator Guoping Feng. “You can put these mutations in animal models to try to understand how this mutation affects brain development, circuit formation, circuit function, and behavior.” Feng is also the James W. (1963) and Patricia T. Poitras Professor of Brain and Cognitive Sciences at MIT.

In work supported by the Poitras Center, the Stelling Family Research Fund, and the Yang Tan Collective at MIT, Feng’s lab has engineered three strains of mice that carry ultra-rare schizophrenia-associated mutations. Their first significant findings come from mice with a mutation in a gene called Grin2a. People who inherit a dysfunctional Grin2a gene, which neurons need to detect and respond to a signaling molecule called NMDA, are 20 times more likely to develop schizophrenia than people in whom Grin2a is intact.
Tingting Zhou, a postdoctoral researcher in Feng’s lab, says the team had to think carefully about how to assess mice for schizophrenia-like symptoms. You can’t ask mice about hallucinations or delusions. Instead, Zhou designed an experiment that tested how well mice use new information to update their beliefs about the world—a process that is thought to be impaired in people who experience delusions.
To illustrate how failure to update beliefs can skew someone’s ideas about reality, Zhou describes a situation in which a person watches a stranger reach for something in their pocket, fearing that person intends to harm them. Then, the stranger’s hand emerges with a lollipop. The new information should alleviate concern—but a person with schizophrenia might hold on to their original belief, convinced the lollipop-holding stranger is a threat.
In Zhou’s experiments testing animals’ belief-updating abilities, mice had to keep up with changing information to earn as many treats as possible. Those with the Grin2a mutation were slow to adapt when experimenters adjusted the relative values of their choices. “Once the animal learns something, it’s very hard for them to update the information,” Zhou explains.
Zhou and Feng linked this behavioral difference to abnormally low activity in a part of the brain called the mediodorsal thalamus. The mediodorsal thalamus acts like a switchboard in the brain, routing and coordinating information between different parts of the cortex to support thinking, decision-making, and flexible behavior. Studies with patients have implicated this region in schizophrenia as well, showing that it has fewer cells and is less active in people with the disorder than those without.
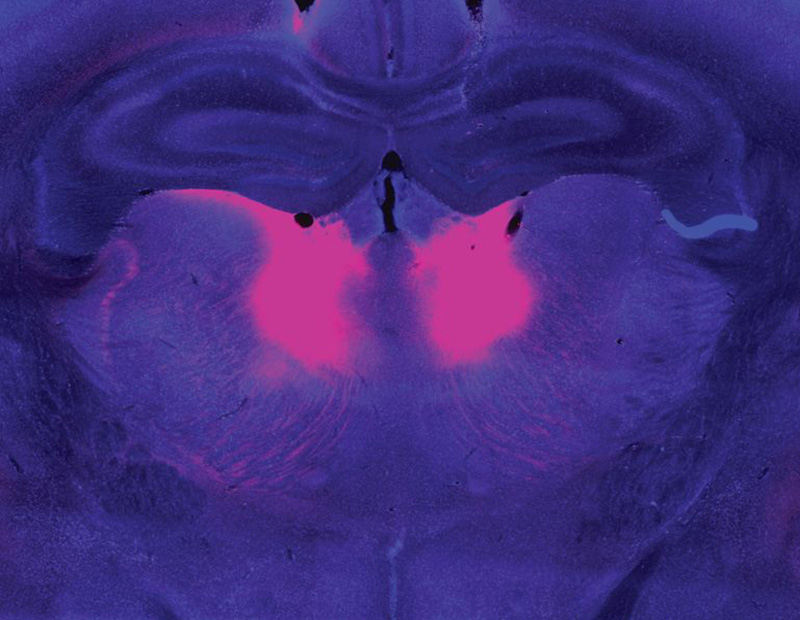
Feng’s lab and others are now looking for belief-updating deficits in other genetic models of schizophrenia. “The goal is to look at whether this is a converging mechanism…then you can start to look at what other [brain] regions are involved,” he says.
In mice with Grin2a mutations, the researchers were able to restore normal belief updating by activating neurons in the mediodorsal thalamus, offering hope that manipulating the same circuitry might benefit patients. “It will not be easy,” Feng says, “but at least you have something you can work on. Previously, it was just very hard to imagine how to develop a new therapeutic for schizophrenia.”
Internal noise
It’s not just the genes associated with schizophrenia that differ across affected individuals. The symptoms of the disorder vary, too. People experience some combination of delusions, hallucinations, disorganized speech, and cognitive problems—but none of these are experienced by everyone with the disorder. This heterogeneity complicates the diagnosis, treatment, and study of schizophrenia. For this reason, some researchers are focusing their efforts on understanding its individual symptoms.
Evelina Fedorenko, a McGovern Investigator and associate professor of brain and cognitive sciences, specializes in understanding how the brain processes speech and language. But recently, her group has teamed up with physician-researcher Ann Shinn at McLean Hospital to begin exploring why some people hear voices when no one is speaking.
About three out of four people with schizophrenia experience auditory hallucinations, which most commonly involve voices.
These hallucinations can be distressing, sometimes involving threatening language or commands to cause harm. Some people with mood disorders or post-traumatic stress disorder also hear them.

Fellow in Evelina Fedorenko’s lab. Photo: Steph Stevens
To investigate, Tamar Regev, a research scientist in the Fedorenko lab, asked people who experience auditory hallucinations to listen to different kinds of sounds inside an MRI scanner, then compared how their brains responded versus the brains of people without auditory hallucinations. Her study included participants with schizophrenia and bipolar disorder, both with and without a history of auditory hallucinations, as well as healthy controls.
Inside the scanner, participants listened to three kinds of audio: spoken language, gibberish, and gibberish so scrambled that it barely resembled speech. Regev analyzed how these sounds impacted activity in areas the brain uses to process auditory input at different levels: a part of the auditory cortex that is sensitive to all sounds; a higher-level region within the auditory cortex that usually responds to anything that sounds like speech, even if its content is unclear; and the brain’s language-processing network, which is called on to understand the content of speech, as well as written or signed communications.
Regev found that in people with hallucinations, the part of the brain that usually responds only to language responded to meaningless speech as well. “In this pathway from auditory to speech to language processing, the stimuli that should be filtered out somewhere on the way are now passing to higher stations,” she explains. While auditory hallucinations don’t require external sounds, Fedorenko and Regev propose that the brain’s language areas might be similarly activated by “internal noise” in auditory circuits.
Scrambled language
In people who experience auditory hallucinations, the brain’s language regions respond to sounds that aren’t language–including scrambled meaningless gibberish. Below is a sample gibberish clip used in Fedorenko’s study.
Early identification
McGovern scientists have also used brain imaging to investigate what happens in the brain before people develop clear symptoms of schizophrenia. The disorder is usually diagnosed in adolescence or young adulthood, when patients exhibit the first signs of psychosis—but its origins in the brain likely take root years before that.
“One of the things we’re super interested in is, can you identify people at risk early on, before they have a big problem,” says McGovern Investigator John Gabrieli, whose work is also supported by the Poitras Center and the Stelling Family Research Fund. That might give clinicians an opportunity to intervene and lessen or prevent the disorder’s most devastating effects, he says.
Gabrieli and his colleagues have studied the brains of children who, because they have a parent or sibling with schizophrenia, have an elevated risk of developing the disorder themselves. They found that a system called the default mode network (DMN), which is overactive in adults with schizophrenia, is already working overtime when children in this high-risk group are seven- to 12-years-old.
Gabrieli explains that the DMN is active when people are not actively engaged in an activity or thinking about the external world. “It turns on when you think about your family, your values, your hopes for the future, or important events of your life. It’s almost like a system of who /you are,” he says. Hallucinations and delusions experienced by people with schizophrenia may be associated with overactivity in this network.
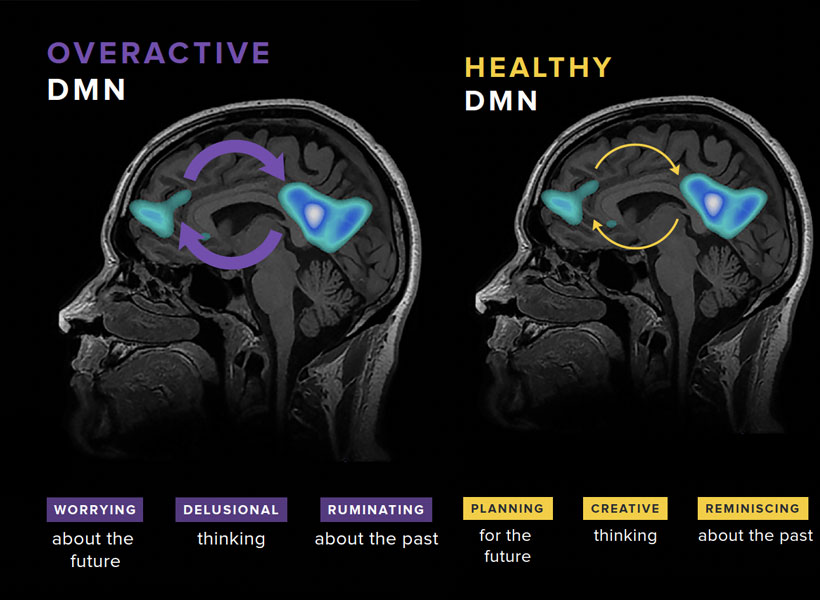
“They’re kind of living in their internal world of beliefs, as opposed to the reality that most of us occupy,” Gabrieli explains.
He and his colleagues think overactivity in the DMN might make people vulnerable to schizophrenia—and their data show this atypical activity can be detected many years before the core symptoms of schizophrenia appear. With further validation, children with hyperactivity of the DMN might be candidates for early intervention.
With new and better interventions, the ability to identify people who may be on a path toward schizophrenia will be even more impactful—underscoring the need for continued research on multiple fronts. A recent gift of $8 million to the Poitras Center from Patricia and James Poitras is helping accelerate this work in labs at the McGovern Institute and beyond.