The brain’s capacity to use and understand language expands rapidly in the first years of life, as babies start to make sense of the words they hear and eventually begin to piece together sentences of their own. The language-processing parts of the brain that make this possible continue to evolve in older children, as they expand their vocabularies and learn to use language more flexibly.
Scientists at MIT’s McGovern Institute have captured snapshots of the developing language-processing network in brain scans of hundreds of children and adolescents. Their data, reported on May 16 in the journal Nature Communications, show that the network continues to mature, becoming better integrated and increasingly responsive until around age 16. But they also found that a key feature of the adult language network is established early on: its localization in the left side of the brain.
Language lateralization
It is well known that using language is mostly the job of the left hemisphere. As adults, we call on the language-processing regions there when we read, write, speak, or listen to others talk. But there was some question as to whether this left lateralization is established early in life, or might instead emerge as the language network matures, with both sides of the brain contributing to language in childhood.
To find out, researchers needed to see young brains in action—and several McGovern Institute labs had collected exactly the right kind of data. Groups led by Associate Professor of Brain and Cognitive Sciences Evelina Fedorenko, John Gabrieli, the Grover Hermann Professor of Health Sciences and Technology, and Rebecca Saxe, the John W. Jarve (1978) Professor of Brain and Cognitive Sciences teamed up to share brain scans from children, adolescents, and adults and compare how their brains responded to language.
In studies aimed at better understanding a variety of cognitive functions and developmental disorders, the three teams had all collected functional MRI data while subjects participated in “language localizer” tasks—an approach the Fedorenko lab developed to map the language-processing network in a person’s brain. By monitoring brain activity with functional MRI as people engage in both language tasks and non-linguistic tasks, researchers can identify parts of the brain that are exclusively dedicated to language processing, whose precise anatomic location varies across individuals.
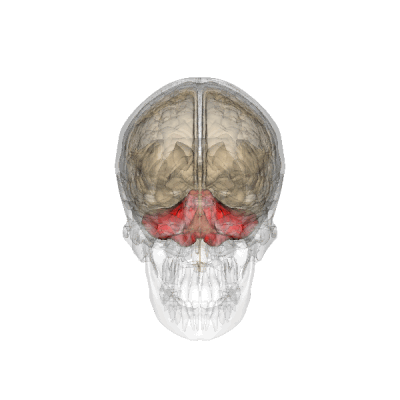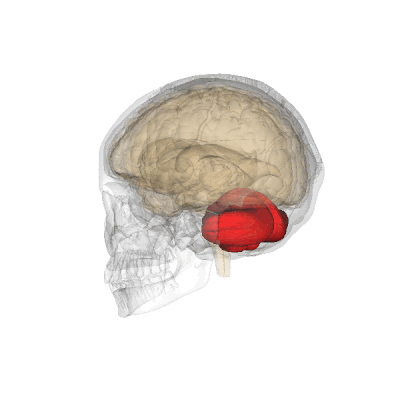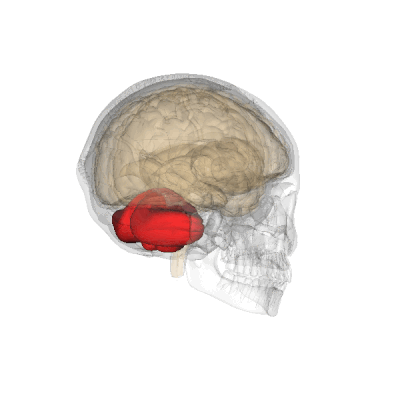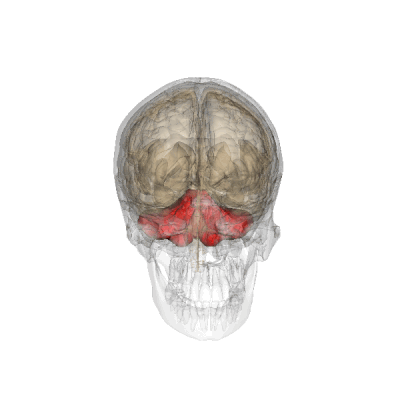
To activate the language network, the researchers had children listen to stories inside the MRI scanner. Depending on their age, some heard excerpts of Alice in Wonderland, some listened to podcasts and TED talks, and others heard shorter, simpler stories. To watch their brains during a non-linguistic task, the researchers had the children listen to nonsense words.
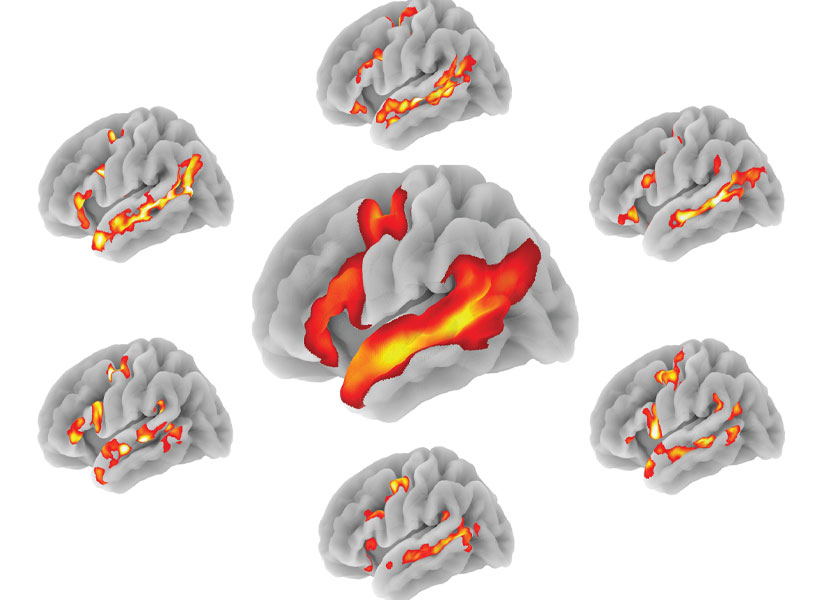
Across the data from the three labs, which included children between the ages of four and 16, as well as adults for comparison, the team saw clear developmental changes in the brain’s response to language. “The integration of the system—how well different subregions of the system correlated with each other and worked together during language processing—was stronger in older children as compared to younger children,” says Ola Ozernov-Palchik, a research scientist in Gabrieli’s lab and a research assistant professor at Boston University. The system was also more strongly activated by language in older children, which may reflect their growing comprehension of what they hear.
But strikingly, almost all language processing happened on the left side of the brain, even in the youngest subjects. “From age four on, it seems just as lateralized as in an adult,” Gabrieli says.
Language and developmental disorders
The researchers say this finding has implications for understanding developmental conditions that impact language, including autism and dyslexia. The right side of the brain frequently gets more involved in language processing in people with these conditions than it does in typically developing children. “Almost every single developmental disorder that’s associated with language has a theory that’s related to language lateralization,” Ozernov-Palchik says.
The reason for more bilateral language processing in some disorders is debated. One idea has been that some people might use both sides of their brain for language processing because their brains are less mature. If the right side of the brain processes language early in life, scientists had reasoned, it might simply continue to do so for longer in people with autism or dyslexia than it does in neurotypical individuals. But if most people use the left side of their brains for language even when they are young, the difference can’t be attributed to a developmental delay. Other developmental differences might cause bilateral language processing instead.
The researchers don’t have the full picture yet; they still need to know what parts of the brain process language in children younger than four. Likewise, they would like to know what the brain areas that become the language network are doing in the first months of life, when infants aren’t using language yet. They are eager to find out, both to understand fundamentals of brain development and to shed light on developmental disorders. “I think understanding that normal trajectory is really critical for interpreting what a deviation from that trajectory is,” says Amanda O’Brien, a former graduate student in Gabrieli’s lab who is now a postdoctoral fellow at Harvard.
One reason people thought lateralization might develop gradually is because damage to the left hemisphere of the brain impacts language abilities differently, depending on when it occurs. “If you have damage to the left hemisphere as an adult, you’re very likely to end up with some form of aphasia, at least temporarily,” Fedorenko explains. “But a lot of the time, with early damage to the left hemisphere, you grow up and you’re totally fine. The language can just develop in the right hemisphere.”
Some scientists suspected that the right side of the brain was able to take over language processing in children who suffered early-life brain damage because it was already participating in this function at the time. But the team’s findings suggest the developing brain may be nimbler than that. “Our data tell you that this early plasticity apparently happens in spite of the fact that by age four, we see these very strongly lateralized responses already,” Fedorenko says.