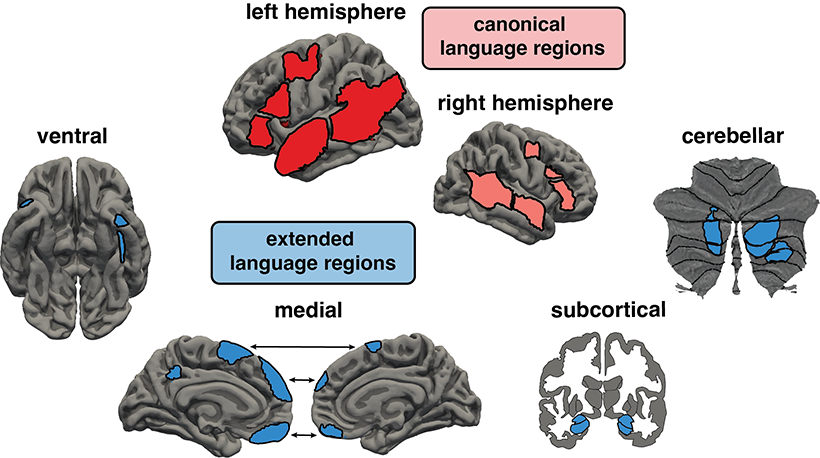
Some people find it useful to talk through their problems—but language isn’t necessary for logical reasoning, cognitive neuroscientists at MIT’s McGovern Institute say. In research published today in the journal PNAS, researchers led by McGovern Institute investigator Evelina Fedorenko have shown that people can perform well on tasks that require logical reasoning even if their language abilities are severely impaired. What’s more, brain imaging shows that language-processing parts of the brain are not called on for logical reasoning. Fedorenko is also an associate professor of brain and cognitive sciences at MIT.
Philosophers, linguists, and cognitive scientists have debated the relationship between language and thought for thousands of years, with many arguing that we use language to think. There are good reasons to suspect a close relationship between logic and language, acknowledges Hope Kean, a postdoctoral researcher and former ICoN graduate fellow in Fedorenko’s lab. “Abstract thinking has properties that look a lot like language,” she says, pointing to structural similarities: “You can decompose a thought into subcomponents, like little atoms of logical propositions, and you can combine them in a hierarchical manner to make more complex structured rules, very akin to language.”
But she and Fedorenko suspected that while we largely depend on language to communicate about logical reasoning—from presenting a problem to explaining how we have arrived at conclusions—the brain might use a separate system for the reasoning itself. “There are aspects of thinking that seem to go beyond some of the limitations of language,” Kean explains. Logical reasoning demands precision that language often lacks. And language is linear, progressing one word at a time, whereas evaluating available information to reach logical conclusions can require thinking in less linear ways.
Logical reasoning
These observations left Kean curious about how the brain handles logical reasoning. It’s a particularly difficult question to answer scientifically, because it’s hard to take language out of the equation when working with human study participants. But Fedorenko’s team did just that by collaborating with Rosemary Varley, a neuroscientist at University College London who studies acquired language disorders, and her team.
Together, the scientists worked with two patients who had experienced stroke that damaged language-processing parts of their brains, leaving them with severe impairments in both understanding and producing language. They designed language-free logic games in which participants were asked to infer relationships between sets of numbers. Given two lists, they had to figure out the hidden rule that turned one list into the other, such as reversing the digits or removing numbers above a certain value. Once they thought they’d discovered the rule, they had to apply it to new examples. In a second game, participants were presented a set of geometric patterns and asked to identify another pattern to complete the matrix.
As participants solved increasingly difficult puzzles, it became clear that people don’t need language for this kind of reasoning. Patients with language impairments solved the problems as well as a control group and were even able to communicate the rules they inferred using gestures or with a sketch. “It really upends a theory that says that symbolic rule induction is not possible without linguistic capacities,” says Kean.
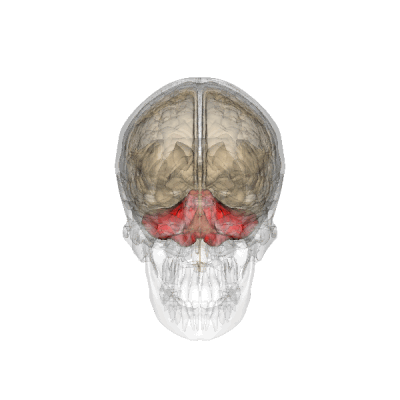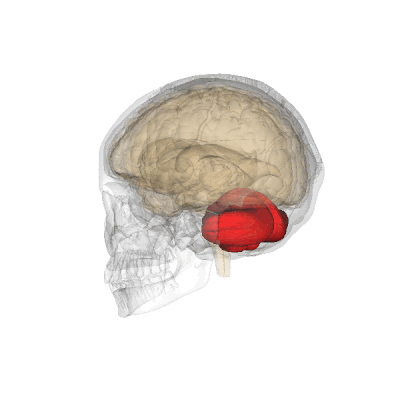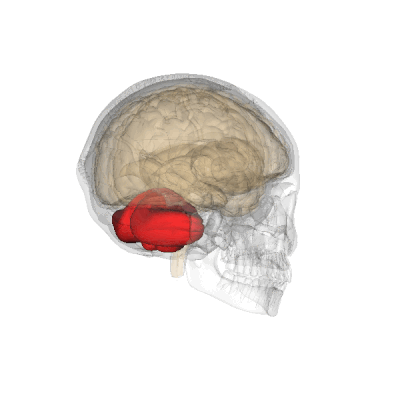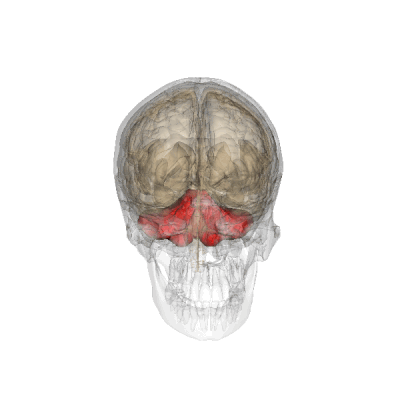
Alongside this part of the study, Kean and colleagues also used functional brain imaging to study what happens in the brains of healthy adults when they are engaged in logical reasoning. Participants in this part of the study visited MIT for a series of MRI scans, which captured images of their brain activity during an array of tasks. In addition to completing different kinds of logic games inside the scanner, participants were asked to engage in tasks designed to map the language-processing parts of their brain. Another set of tasks was used to map each person’s Multiple Demand network—a distributed brain system that supports complex problem solving.
These neurotypical participants completed logic games similar to those used with the language-impaired patients. They were also presented with problems that required syllogistic reasoning, using “if-then” statements such as “If the ball is red, then it is big. The ball is red. Is the ball big?” The team varied the difficulty of the logic puzzles so they could see which brain areas became more active when the need for logical reasoning intensified. Likewise, they looked for changes in brain activity when participants had to infer a hidden rule versus simply applying a rule they’d been given.
Here too, a separation between language and logic was clear: The MRI scans showed the brain’s language system is not engaged for either inductive reasoning (when participants identified hidden rules) or deductive reasoning (when they assessed the validity of syllogistic conclusions). Surprisingly, the Multiple Demand network, which many scientists had suspected was important for logical reasoning, was engaged during inductive reasoning but didn’t seem to get involved in deductive reasoning—a finding Kean is building on in her ongoing work.
For Fedorenko and Kean, the findings are strong support for a separation of logic and language in the brain. They add to previous findings from Fedorenko’s lab showing that other types of thinking, such as object categorization and social reasoning, also do not rely on language.
Acquired language impairments and AI
The researchers say these findings have important implications for how we think about acquired language impairments, or aphasia. Specialists who work with people with aphasia have long recognized that loss of language does not mean loss of intelligence. People with aphasia can continue to enjoy playing chess, solving sudoku puzzles, or being in charge of the family’s finances. But it is common for others to confuse their communicative difficulties with thinking difficulties.
“This research adds to a growing body of work establishing that even severely aphasic individuals can preserve their ability for abstract logical thought—a defining feature of our species,” Fedorenko says. “We should continue to educate the public that linguistic difficulties—in aphasia, but also in those with developmental language conditions, such as stuttering, or those who do not speak English natively—are not indicative of how smart or capable someone is.”
There could be implications for artificial intelligence, too. Large language models like ChatGPT and Claude are trained entirely on text and use text as their output—yet they convincingly simulate some kinds of human reasoning. Exploring the differences between these models and the human brain, where language and abstract logical thought are distinct, might offer useful insights to inform future models, Kean says.
When it comes to understanding how the human brain reasons, Kean calls this a new frontier in the geography of thought—and she says it’s one she is eager to explore.