Michale Fee, the Glen V. and Phyllis F. Dorflinger Professor of Neuroscience and head of the Department of Brain and Cognitive Sciences, and Fan Wang, a professor of brain and cognitive sciences, have been elected to join the National Academy of Sciences (NAS). Fee and Wang, who are also investigators at the McGovern Institute for Brain Research, were elected by current NAS members in recognition of their “distinguished and continuing achievements in original research.”
The NAS is a private, nonprofit institution that was established under a congressional charter signed by President Abraham Lincoln in 1863. It recognizes achievement in science by election to membership, and — with the National Academy of Engineering and the National Academy of Medicine — provides science, engineering, and health policy advice to the federal government and other organizations. This year, the NAS elected 120 members and 25 international members, including six MIT faculty, bringing the total number of active members to 2,705.
“Election to the National Academy of Sciences by one’s peers is a great honor for a scientist in the United States,” says McGovern Institute Director Robert Desimone. “Michale and Fan represent the very best of our research community and we are tremendously proud of their accomplishments and this well-deserved recognition.”
Michale Fee’s research explores how the brain learns and generates complex sequential behaviors. Using the zebra finch as a model system, Fee investigates the neural mechanisms underlying birdsong—a behavior that young birds learn from their fathers through trial and error, much as human infants learn to speak through babbling. His work has revealed that a brain region called the higher vocal center (HVC) functions like an orchestra conductor, precisely controlling the tempo and timing of song production. Other work from his lab has shown how this same circuit helps to store a memory of the father’s song, how baby birds babble in order to practice their song, and how this vocal practice is translated to song learning by listening to themselves sing.
These findings extend far beyond birdsong—the neural circuits controlling birdsong learning are closely related to human brain circuits disrupted in Parkinson’s and Huntington’s disease. Insights from Fee’s research could reveal new clues to the causes and potential treatments of these complex brain disorders.
Fee’s appointment in 2021 as head of the Department of Brain and Cognitive Sciences continues the department’s tradition of being led by scientists whose exemplary work makes MIT a world leader in brain science.
Fan Wang investigates the neural circuits that govern the dynamic interactions between brain and body, exploring how the brain generates sensory perceptions and controls movement. Wang, who is also the co-director of the K. Lisa Yang and Hock E. Tan Center for Molecular Therapeutics, uses cutting-edge techniques including optogenetics, in vivo electrophysiology, and in vivo imaging, to make discoveries with profound clinical implications.
By developing innovative tools to study how brain circuits work, Wang discovered distinct populations of neurons activated by anesthesia that can suppress pain without blocking sensation, and can calm anxiety by regulating automatic body functions like heart rate. She also identified the brain circuits controlling rhythmic movements essential for exploration and communication. Together, these findings reveal how emotion, physiology, movement, and consciousness are deeply interconnected.
Wang combines rigorous basic neuroscience with a commitment to translating her discoveries into therapies that relieve human suffering. Her election to the NAS recognizes her contributions to understanding the brain-body connection and therapeutic potential of her groundbreaking research.
The formal induction ceremony for new NAS members, during which they sign the ledger whose first signatory is Abraham Lincoln, will be held at the Academy’s annual meeting in Washington D.C. next spring.
Schizophrenia, a complex and variable psychiatric disorder, changes people’s perceptions of reality. People with schizophrenia may hear, see, or sense things that aren’t there, and they often hold firm to mistaken ideas about the world despite strong evidence to the contrary. As if these changes aren’t disruptive enough, they are usually accompanied by cognitive difficulties and disorganized thinking.
Scientists at the McGovern Institute’s Poitras Center for Psychiatric Disorders Research are looking for clues into the origins of the disorder and its symptoms so they can help guide the development of new treatments. Encouragingly, they are beginning to uncover the brain changes that reshape reality for people with schizophrenia.
Genetic clues
Researchers who want to study the root causes of a disease often turn to genetics for clues—and the genetics of schizophrenia are complicated. Hundreds of different genes seem to shape people’s risk of developing the disorder, most of which nudge risk only slightly. For most people, it seems to be the cumulative effect of these genes and how they intersect with other risk factors, like stress and prenatal complications, that determine who develops schizophrenia and who does not.
Gene variants that substantially impact the risk of schizophrenia are expected to reveal more about the underlying biology of the disorder than genes whose individual impact is minor. But these variants are rare, and it took a massive study to find them. In 2022, scientists at the Broad Institute’s Stanley Center for Psychiatric Research reported that after analyzing the DNA of more than 24,000 people with schizophrenia, they had identified mutations in 10 genes that dramatically increased the risk of the disorder.
“I think this is exciting, because for the first time, you can actually have an animal model based onhuman genetics findings,” says McGovern Institute and Stanley Center Investigator Guoping Feng. “You can put these mutations in animal models to try to understand how this mutation affects brain development, circuit formation, circuit function, and behavior.” Feng is also the James W. (1963) and Patricia T. Poitras Professor of Brain and Cognitive Sciences at MIT.
Guoping Feng (right) and his postdoctoral researcher Tinting Zhou (left) examine a mouse brain carrying a genetic mutation associated with schizophrenia. Photo: Steph Stevens
In work supported by the Poitras Center, the Stelling Family Research Fund, and the Yang Tan Collective at MIT, Feng’s lab has engineered three strains of mice that carry ultra-rare schizophrenia-associated mutations. Their first significant findings come from mice with a mutation in a gene called Grin2a. People who inherit a dysfunctional Grin2a gene, which neurons need to detect and respond to a signaling molecule called NMDA, are 20 times more likely to develop schizophrenia than people in whom Grin2a is intact.
Tingting Zhou, a postdoctoral researcher in Feng’s lab, says the team had to think carefully about how to assess mice for schizophrenia-like symptoms. You can’t ask mice about hallucinations or delusions. Instead, Zhou designed an experiment that tested how well mice use new information to update their beliefs about the world—a process that is thought to be impaired in people who experience delusions.
To illustrate how failure to update beliefs can skew someone’s ideas about reality, Zhou describes a situation in which a person watches a stranger reach for something in their pocket, fearing that person intends to harm them. Then, the stranger’s hand emerges with a lollipop. The new information should alleviate concern—but a person with schizophrenia might hold on to their original belief, convinced the lollipop-holding stranger is a threat.
In Zhou’s experiments testing animals’ belief-updating abilities, mice had to keep up with changing information to earn as many treats as possible. Those with the Grin2a mutation were slow to adapt when experimenters adjusted the relative values of their choices. “Once the animal learns something, it’s very hard for them to update the information,” Zhou explains.
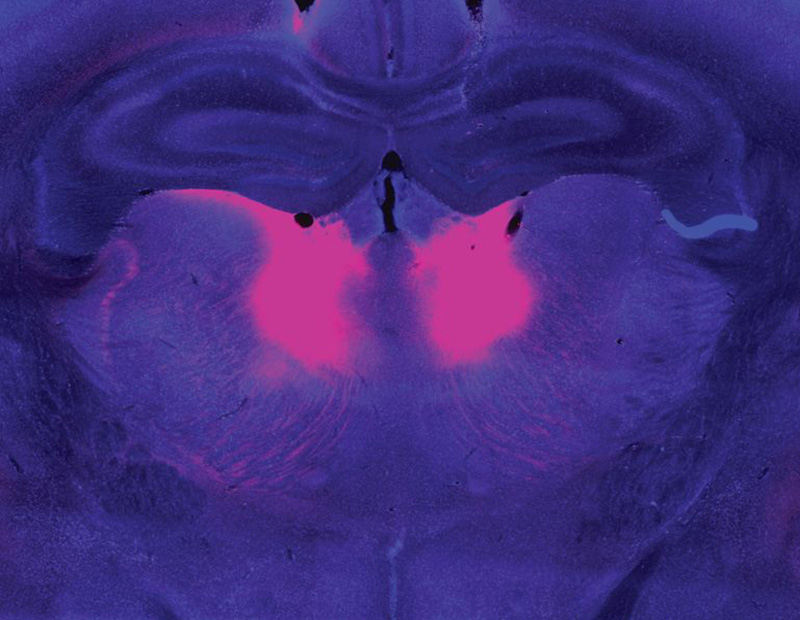
Zhou and Feng linked this behavioral difference to abnormally low activity in a part of the brain called the mediodorsal thalamus. The mediodorsal thalamus acts like a switchboard in the brain, routing and coordinating information between different parts of the cortex to support thinking, decision-making, and flexible behavior. Studies with patients have implicated this region in schizophrenia as well, showing that it has fewer cells and is less active in people with the disorder than those without.
The mediodorsal thalamus (pink) is less active in people with schizophrenia and mouse models of the disease. Image: Guoping Feng, Tingting Zhou
Feng’s lab and others are now looking for belief-updating deficits in other genetic models of schizophrenia. “The goal is to look at whether this is a converging mechanism…then you can start to look at what other [brain] regions are involved,” he says.
In mice with Grin2a mutations, the researchers were able to restore normal belief updating by activating neurons in the mediodorsal thalamus, offering hope that manipulating the same circuitry might benefit patients. “It will not be easy,” Feng says, “but at least you have something you can work on. Previously, it was just very hard to imagine how to develop a new therapeutic for schizophrenia.”
Internal noise
It’s not just the genes associated with schizophrenia that differ across affected individuals. The symptoms of the disorder vary, too. People experience some combination of delusions, hallucinations, disorganized speech, and cognitive problems—but none of these are experienced by everyone with the disorder. This heterogeneity complicates the diagnosis, treatment, and study of schizophrenia. For this reason, some researchers are focusing their efforts on understanding its individual symptoms.
Evelina Fedorenko, a McGovern Investigator and associate professor of brain and cognitive sciences, specializes in understanding how the brain processes speech and language. But recently, her group has teamed up with physician-researcher Ann Shinn at McLean Hospital to begin exploring why some people hear voices when no one is speaking.
About three out of four people with schizophrenia experience auditory hallucinations, which most commonly involve voices.
These hallucinations can be distressing, sometimes involving threatening language or commands to cause harm. Some people with mood disorders or post-traumatic stress disorder also hear them.
Tamar Regev was the 2022–2024 Poitras Center Postdoctoral Fellow in Evelina Fedorenko’s lab. Photo: Steph Stevens
To investigate, Tamar Regev, a research scientist in the Fedorenko lab, asked people who experience auditory hallucinations to listen to different kinds of sounds inside an MRI scanner, then compared how their brains responded versus the brains of people without auditory hallucinations. Her study included participants with schizophrenia and bipolar disorder, both with and without a history of auditory hallucinations, as well as healthy controls.
Inside the scanner, participants listened to three kinds of audio: spoken language, gibberish, and gibberish so scrambled that it barely resembled speech. Regev analyzed how these sounds impacted activity in areas the brain uses to process auditory input at different levels: a part of the auditory cortex that is sensitive to all sounds; a higher-level region within the auditory cortex that usually responds to anything that sounds like speech, even if its content is unclear; and the brain’s language-processing network, which is called on to understand the content of speech, as well as written or signed communications.
Regev found that in people with hallucinations, the part of the brain that usually responds only to language responded to meaningless speech as well. “In this pathway from auditory to speech to language processing, the stimuli that should be filtered out somewhere on the way are now passing to higher stations,” she explains. While auditory hallucinations don’t require external sounds, Fedorenko and Regev propose that the brain’s language areas might be similarly activated by “internal noise” in auditory circuits.
Scrambled language
In people who experience auditory hallucinations, the brain’s language regions respond to sounds that aren’t language–including scrambled meaningless gibberish. Below is a sample gibberish clip used in Fedorenko’s study.
Early identification
McGovern scientists have also used brain imaging to investigate what happens in the brain before people develop clear symptoms of schizophrenia. The disorder is usually diagnosed in adolescence or young adulthood, when patients exhibit the first signs of psychosis—but its origins in the brain likely take root years before that.
“One of the things we’re super interested in is, can you identify people at risk early on, before they have a big problem,” says McGovern Investigator John Gabrieli, whose work is also supported by the Poitras Center and the Stelling Family Research Fund. That might give clinicians an opportunity to intervene and lessen or prevent the disorder’s most devastating effects, he says.
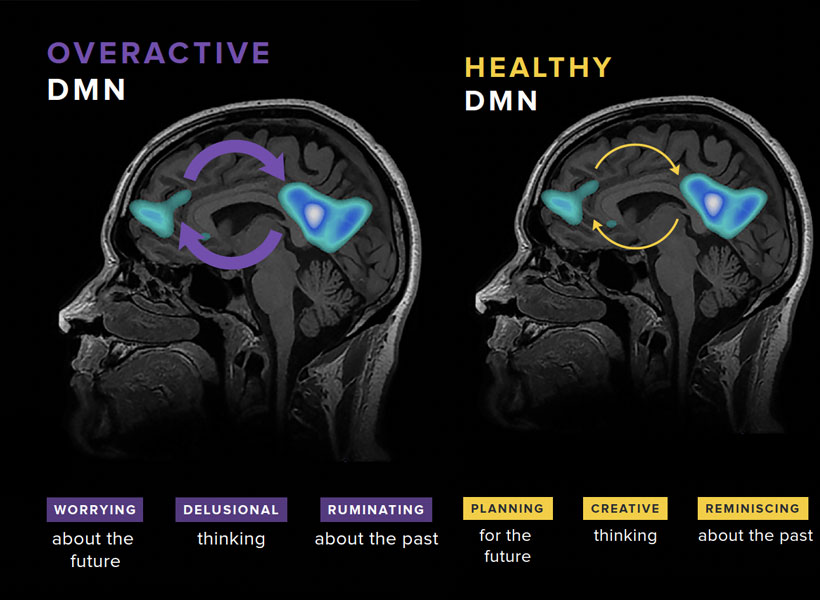
Gabrieli and his colleagues have studied the brains of children who, because they have a parent or sibling with schizophrenia, have an elevated risk of developing the disorder themselves. They found that a system called the default mode network (DMN), which is overactive in adults with schizophrenia, is already working overtime when children in this high-risk group are seven- to 12-years-old.
Gabrieli explains that the DMN is active when people are not actively engaged in an activity or thinking about the external world. “It turns on when you think about your family, your values, your hopes for the future, or important events of your life. It’s almost like a system of who /you are,” he says. Hallucinations and delusions experienced by people with schizophrenia may be associated with overactivity in this network.
The default mode network (DMN) is a large-scale brain network that is active when a person is not focused on the outside world and the brain is at wakeful rest. The DMN is often over-engaged in adolescents with depression and anxiety, as well as teens at risk for these and other disorders like schizophrenia (left). DMN activation and connectivity can be “tuned” to a healthier state through the practice of mindfulness (right).
“They’re kind of living in their internal world of beliefs, as opposed to the reality that most of us occupy,” Gabrieli explains.
He and his colleagues think overactivity in the DMN might make people vulnerable to schizophrenia—and their data show this atypical activity can be detected many years before the core symptoms of schizophrenia appear. With further validation, children with hyperactivity of the DMN might be candidates for early intervention.
With new and better interventions, the ability to identify people who may be on a path toward schizophrenia will be even more impactful—underscoring the need for continued research on multiple fronts. A recent gift of $8 million to the Poitras Center from Patricia and James Poitras is helping accelerate this work in labs at the McGovern Institute and beyond.
What if a technology could reanimate parts of the body that have lost their connection to the brain — like a bladder that can no longer empty due to a spinal cord injury, or intestines that can’t push food forward due to Crohn’s disease? What if this technology could also send sensations such as hunger or touch back to the brain?
New MIT research offers a glimpse into this future. In a study published today in Nature Communications, the researchers introduce a novel myoneural actuator (MNA) that reprograms living muscles into fatigue-resistant, computer-controlled motors that can be implanted inside the body to restore movement in organs.
“We’ve built an interface that leverages natural pathways used by the nervous system so that we can seamlessly control organs in the body, while also enabling the transmission of sensory feedback to the brain,” says Hugh Herr, senior author of the study, a professor of Media Arts and Sciences at the MIT Media Lab, co-director of the K. Lisa Yang Center for Bionics, and an associate member of the McGovern Institute for Brain Research at MIT. The study was co-led by Herr’s postdoctoral associate Guillermo Herrera-Arcos and former postdoc Hyungeun Song.
By repurposing existing muscle in the body, the researchers have developed the first “living” implant that uses rewired sensory nerves to revive paralyzed organs — which may present a new genre of medicine where a person’s own tissue becomes the hardware.
Rewiring the brain-body interface
Many scientists have toiled to restore function in paralyzed organs, but it’s extremely challenging to design a technology that both communicates with the nervous system and doesn’t fatigue over time. Some have tried to insert miniaturized actuators — small machines that can power bionic limbs — into the body. However, Herrera-Arcos says “it’s hard to make actuators at the centimeter level and they aren’t very efficient.” Others have focused on creating muscle tissue in the lab, but building muscles cell by cell is time-intensive and far from ready for human use.
Herr’s team tried something different.
“We engineered existing muscles to become an actuator, or motor, that reinstates motion in organs,” says Song.
To do this, the researchers had to navigate the delicate dynamics within the nervous system. The actuator would have to interface with the nervous system to work properly, but it must also somehow evade the brain’s control. “You don’t want the brain to consciously control the muscle actuator because you want the actuator to automatically control an organ, like the heart,” explains Herrera-Arcos. Establishing a computer-controlled muscle to move organs could ensure automatic function and also bypass damaged brain pathways.
Incorporating motor neurons into the actuator may help generate movement, but these neurons are directly controlled by the brain. “Sensory neurons, however, are wired to receive, not to command,” explains Song. “We thought we could leverage this dynamic and reroute motor signals through sensory fibers, making a computer — rather than the brain — the muscle’s new command center.”
To achieve this, sensory nerves would need to fuse fluidly with muscle, and scientists had not yet determined if this was possible. Remarkably, when the team replaced motor nerves in rodent muscle with sensory ones, “the sensory nerves reinnervated the muscles and formed functional synapses. It’s a tremendous discovery,” says Herrera-Arcos.
Sensory neurons not only enabled the use of a digital controller but also helped curb muscle fatigue — increasing fatigue resistance in rodent muscle by 260 percent compared to native muscles. That’s because muscle fatigue depends largely on the diameter of the axons, or cable-like projections that innervate muscles. Motor neuron axons vary greatly in size, and when a motor nerve is electrically stimulated, the largest axons fire first — exhausting the muscle quickly. However, sensory axons are all nearly the same size, so the signal is broadcast more evenly across muscle fibers, avoiding fatigue, explains Herrera-Arcos.
Designing a biohybrid system
They combined all of these elements into a fatigue-resistant biohybrid motor called a myoneural actuator (MNA). By wrapping their actuator around a paralyzed intestine in a rodent, the researchers reinstated the organ’s squeezing motion. They also successfully controlled rodent calf muscles in an experiment designed to mimic residual muscle in human lower-limb amputations. Importantly, the MNA system transmitted sensory signals to the brain. “This suggests that our technology could seamlessly link organs to the brain. For example, we might be able to make a paralyzed stomach relay hunger,” explains Song.
Bringing their MNA to clinic will require further testing in larger animal models, and eventually, humans. But if it passes the regulatory gauntlet, their system could pave a smoother and safer path toward reviving static organs. Implanting MNAs would require a surgery that is already commonplace in clinic, the researchers say, and their system might be simpler and safer to implement than mechanical devices or organ transplants that introduce foreign material into the body.
The team is hopeful that their new technology could improve the lives of millions living with organ dysfunctions. “Today’s solutions are mostly synthetic: pacemakers and other mechanical assist devices. A living muscle actuator implanted alongside a weakened organ would be part of the body itself. That is a category of medicine different from anything seen in clinic,” explains Herrera-Arcos.
Song says that skin is of special interest. “Hypothetically, we could wrap MNAs around skin grafts to relay tactile feedback, such as strain or tension, which is currently missing for users of prostheses.” Their technology could even augment virtual reality systems, too. “The idea is that, if we couple the MNA system to skin and muscles, a person could feel what their virtual avatar is touching even though their real body isn’t moving,” says Song.
“Our research is on the brink of giving new life to various parts and extensions of the body,” adds Herrera-Arcos. “It’s exciting to think that our system could enhance human potential in ways that once only belonged to the realm of science fiction.”
This research was funded in part by the Yang Tan Collective at MIT, K. Lisa Yang Center for Bionics at MIT, Nakos Family Bionics Research Fund at MIT, and the Carl and Ruth Shapiro Foundation.
Experience is a powerful teacher—and not every experience has to be our own to help us understand the world. What happens to others is instructive, too. That’s true for humans as well as for other social animals. New research from scientists at the McGovern Institute shows what happens in the brains of monkeys as they integrate their observations of others with knowledge gleaned from their own experience.
“The study shows how you use observation to update your assumptions about the world,” explains McGovern Institute Investigator Mehrdad Jazayeri, who led the research. His team’s findings, published in the January 7 issue of the journal Nature, also help explain why we tend to weigh information gleaned from observation and direct experience differently when we make decisions. Jazayeri is also a professor of brain and cognitive sciences at MIT and an investigator at the Howard Hughes Medical Institute.
“As humans, we do a large part of our learning through observing other people’s experiences and what they go through and what decisions they make,” says Setayesh Radkani, a graduate student in Jazayeri’s lab. For example, she says, if you get sick after eating out, you might wonder if the food at the restaurant was to blame. As you consider whether it’s safe to return, you’ll likely take into account whether the friends you’d dined with got sick too. Your experiences as well as those of your friends will inform your understanding of what happened.
The research team wanted to know how this works: When we make decisions that draw on both direct experience and observation, how does the brain combine the two kinds of evidence? Are the two kinds of information handled differently?
Social experiment
It is hard to tease out the factors that influence social learning. “When you’re trying to compare experiential learning versus observational learning, there are a ton of things that can be different,” Radkani says. For example, people may draw different conclusions about someone else’s experiences than their own, because they know less about that person’s motivations and beliefs. Factors like social status, individual differences, and emotional states can further complicate these situations and be hard to control for, even in a lab.
To create a carefully controlled scenario in which they could focus on how observation changes our understanding of the world, Radkani and postdoctoral fellow Michael Yoo devised a computer game that would allow two players to learn from one another through their experiences. They taught this game to both humans and monkeys.
Their approach, Jazayeri says, goes far beyond the kinds of tasks that are typically studied in a neuroscience lab. “I think it might be one of the most sophisticated tasks monkeys have been trained to perform in a lab,” he says.
Both monkeys and humans played the game in pairs. The object was to collect enough tokens to earn a reward. Players could choose to enter either of two virtual arenas to play—but in one of the two arenas, tokens had no value. In that arena, no matter how many tokens a player collected, they could not win. Players were not told which arena was which, and the winnable and unwinnable arenas sometimes swapped without warning.
Only one individual played at a time, but regardless of who was playing, both individuals watched all of the games. So as either player collected tokens and either did or did not receive a reward, both the player and the observer got the same information. They could use that information to decide which arena to choose in their next round.
Experience outweighs observation
Humans and monkeys have sophisticated social intelligence and both clearly took their partners’ experiences into account as they played the game. But the researchers found that the outcomes of a player’s own games had a stronger influence on each individual’s choice of arena than the outcomes of their partner’s games. “They seem to learn less efficiently from observation, suggesting they tend to devalue the observational evidence,” Radkani says. That distinction was reflected in the patterns of neural activity that the team detected in the brains of the monkeys.
Postdoctoral fellow Ruidong Chen and research assistant Neelima Valluru recorded signals from a part of the brain’s frontal lobe called the anterior cingulate cortex (ACC) as the monkeys played the game. The ACC is known to be involved in social processing. It also integrates information gained through multiple experiences, and seems to use this to update an animal’s beliefs about the world. Prior to the Jazayeri lab’s experiments, this integrative function had only been linked to animals’ direct experiences—not their observations of others.
Consistent with earlier studies, neurons in the ACC changed their activity patterns both when the monkeys played the game and when they watched their partner take a turn. But these signals were complex and variable, making it hard to discern the underlying logic. To tackle this challenge, Chen recorded neural activity from large groups of neurons in both animals across dozens of experiments. “We also had to devise new analysis methods to crack the code and tease out the logic of the computation,” Chen says.
One of the researchers’ central questions was how information about self and other makes its way to the ACC. The team reasoned that there were two possibilities: either the ACC receives a single input on each trial specifying who is acting, or it receives separate input streams for self and other. To test these alternatives, they built artificial neural network models organized both ways and analyzed how well each model matched their neural data. The results suggested that the ACC receives two distinct inputs, one reflecting evidence acquired through direct experience and one reflecting evidence acquired through observation.
The team also found a tantalizing clue about why the brain tends to trust firsthand experiences more than observations. Their analysis showed that the integration process in the ACC was biased toward direct experience. As a result, both humans and monkeys cared more about their own experiences than the experiences of their partner.
Jazayeri says the study paves the way to deeper investigations of how the brain drives social behavior. Now that his team has examined one of the most fundamental features of social learning, they plan to add additional nuance to their studies, potentially exploring how different abilities or the social relationships between animals influence learning.
“Under the broad umbrella of social cognition, this is like step zero,” he says. “But it’s a really important step, because it begins to provide a basis for understanding how the brain represents and uses social information in shaping the mind.”
This research was supported in part by the Yang Tan Collective at MIT.
As people age, their immune system function declines. T cell populations become smaller and can’t react to pathogens as quickly, making people more susceptible to a variety of infections.
To try to overcome that decline, researchers at MIT and the Broad Institute have found a way to temporarily program cells in the liver to improve T-cell function. This reprogramming can compensate for the age-related decline of the thymus, where T cell maturation normally occurs.
Using mRNA to deliver three key factors that usually promote T-cell survival, the researchers were able to rejuvenate the immune systems of mice. Aged mice that received the treatment showed much larger and more diverse T cell populations in response to vaccination, and they also responded better to cancer immunotherapy treatments. Their findings are published in the December 17 issue of the journal Nature.
If developed for use in patients, this type of treatment could help people lead healthier lives as they age, the researchers say.
“If we can restore something essential like the immune system, hopefully we can help people stay free of disease for a longer span of their life,” says Feng Zhang, the James and Patricia Poitras Professor of Neuroscience at MIT, who has joint appointments in the departments of Brain and Cognitive Sciences and Biological Engineering.
Zhang, who is also an investigator at the McGovern Institute for Brain Research at MIT, a core institute member at the Broad Institute of MIT and Harvard, an investigator in the Howard Hughes Medical Institute, and co-director of the K. Lisa Yang and Hock E. Tan Center for Molecular Therapeutics at MIT, is the senior author of the new study. Former MIT postdoc Mirco Friedrich is the lead author of the paper, which appears today in Nature.
A temporary factory
The thymus, a small organ located in front of the heart, plays a critical role in T-cell development. Within the thymus, immature T cells go through a checkpoint process that ensures a diverse repertoire of T cells. The thymus also secretes cytokines and growth factors that help T cells to survive.
However, starting in early adulthood, the thymus begins to shrink. This process, known as thymic involution, leads to a decline in the production of new T cells. By the age of approximately 75, the thymus is greatly reduced.
“As we get older, the immune system begins to decline. We wanted to think about how can we maintain this kind of immune protection for a longer period of time, and that’s what led us to think about what we can do to boost immunity,” Friedrich says.
Previous work on rejuvenating the immune system has focused on delivering T cell growth factors into the bloodstream, but that can have harmful side effects. Researchers are also exploring the possibility of using transplanted stem cells to help regrow functional tissue in the thymus.
The MIT team took a different approach: They wanted to see if they could create a temporary “factory” in the body that would generate the T-cell-stimulating signals that are normally produced by the thymus.
“Our approach is more of a synthetic approach,” Zhang says. “We’re engineering the body to mimic thymic factor secretion.”
For their factory location, they settled on the liver, for several reasons. First, the liver has a high capacity for producing proteins, even in old age. Also, it’s easier to deliver mRNA to the liver than to most other organs of the body. The liver was also an appealing target because all of the body’s circulating blood has to flow through it, including T cells.
To create their factory, the researchers identified three immune cues that are important for T-cell maturation. They encoded these three factors into mRNA sequences that could be delivered by lipid nanoparticles. When injected into the bloodstream, these particles accumulate in the liver and the mRNA is taken up by hepatocytes, which begin to manufacture the proteins encoded by the mRNA.
The factors that the researchers delivered are DLL1, FLT-3, and IL-7, which help immature progenitor T cells mature into fully differentiated T cells.
Immune rejuvenation
Tests in mice revealed a variety of beneficial effects. First, the researchers injected the mRNA particles into 18-month-old mice, equivalent to humans in their 50s. Because mRNA is short-lived, the researchers gave the mice multiple injections over four weeks to maintain a steady production by the liver.
After this treatment, T cell populations showed significant increases in size and function.
The researchers then tested whether the treatment could enhance the animals’ response to vaccination. They vaccinated the mice with ovalbumin, a protein found in egg whites that is commonly used to study how the immune system responds to a specific antigen. In 18-month-old mice that received the mRNA treatment before vaccination, the researchers found that the population of cytotoxic T-cells specific to ovalbumin doubled, compared to mice of the same age that did not receive the mRNA treatment.
The mRNA treatment can also boost the immune system’s response to cancer immunotherapy, the researchers found. They delivered the mRNA treatment to 18-month-old mice, who were then implanted with tumors and treated with a checkpoint inhibitor drug. This drug, which targets the protein PD-L1, is designed to help take the brakes off the immune system and stimulate T cells to attack tumor cells.
Mice that received the treatment showed much higher survival rates and longer lifespan that those that received the checkpoint inhibitor drug but not the mRNA treatment.
The researchers found that all three factors were necessary to induce this immune enhancement; none could achieve all aspects of it on their own. They now plan to study the treatment in other animal models and to identify additional signaling factors that may further enhance immune system function. They also hope to study how the treatment affects other immune cells, including B cells.
Other authors of the paper include Julie Pham, Jiakun Tian, Hongyu Chen, Jiahao Huang, Niklas Kehl, Sophia Liu, Blake Lash, Fei Chen, Xiao Wang, and Rhiannon Macrae.
The research was funded, in part, by the Howard Hughes Medical Institute, the K. Lisa Yang Brain-Body Center, part of the Yang Tan Collective at MIT, Broad Institute Programmable Therapeutics Gift Donors, the Pershing Square Foundation, J. and P. Poitras, and an EMBO Postdoctoral Fellowship.
More than 300 million people worldwide are living with rare disorders — many of which have a genetic cause and affect the brain and nervous system — yet the vast majority of these conditions lack an approved therapy. Because each rare disorder affects fewer than 65 out of every 100,000 people, studying these disorders and creating new treatments for them is especially challenging.
Thanks to a generous philanthropic gift from Ana Méndez ’91 and Rajeev Jayavant ’86, EE ’88, SM ’88, MIT is now poised to fill the gaps in this research landscape. By establishing the Rare Brain Disorders Nexus — or RareNet — at MIT’s McGovern Institute, the alumni aim to convene leaders in neuroscience research, clinical medicine, patient advocacy, and industry to streamline the lab-to-clinic pipeline for rare brain disorder treatments.
“Ana and Rajeev’s commitment to MIT will form crucial partnerships to propel the translation of scientific discoveries into promising therapeutics and expand the Institute’s impact on the rare brain disorders community,” says MIT President Sally Kornbluth. “We are deeply grateful for their pivotal role in advancing such critical science and bringing attention to conditions that have long been overlooked.”
Building new coalitions
Several hurdles have slowed the lab-to-clinic pipeline for rare brain disorder research. It is difficult to secure a sufficient number of patients per study, and current research efforts are fragmented since each study typically focuses on a single disorder (there are more than 7,000 known rare disorders, according to the World Health Organization). Pharmaceutical companies are often reluctant to invest in emerging treatments due to a limited market size and the high costs associated with preparing drugs for commercialization.
Méndez and Jayavant envision that RareNet will finally break down these barriers. “Our hope is that RareNet will allow leaders in the field to come together under a shared framework and ignite scientific breakthroughs across multiple conditions. A discovery for one rare brain disorder could unlock new insights that are relevant to another,” says Jayavant. “By congregating the best minds in the field, we are confident that MIT will create the right scientific climate to produce drug candidates that may benefit a spectrum of uncommon conditions.”
Guoping Feng, the James W. (1963) and Patricia T. Poitras Professor in Neuroscience and associate director of the McGovern Institute for Brain Research at MIT, will serve as RareNet’s inaugural faculty director. Feng holds a strong record of advancing studies on therapies for neurodevelopmental disorders, including autism spectrum disorders, Williams syndrome, and uncommon forms of epilepsy. His team’s gene therapy for Phelan-McDermid syndrome, a rare and profound autism spectrum disorder, has been licensed to Jaguar Gene Therapy and is currently undergoing clinical trials. “RareNet pioneers a unique model for biomedical research — one that is reimagining the role academia can play in developing therapeutics,” says Feng.
An early version of a gene therapy for SHANK3 mutations — linked to a rare brain disorder called Phelan-McDermid syndrome — correctly finds its way to neurons. Image: Feng lab
RareNet plans to deploy two major initiatives: a global consortium and a therapeutic pipeline accelerator. The consortium will form an international network of researchers, clinicians, and patient groups from the outset. It seeks to connect siloed research efforts, secure more patient samples, promote data sharing, and drive a strong sense of trust and goal alignment across the RareNet community. Partnerships within the consortium will support the aim of the therapeutic pipeline accelerator: to de-risk early lab discoveries and expedite their translation to clinic. By fostering more targeted collaborations — especially between academia and industry — the accelerator will prepare potential treatments for clinical use as efficiently as possible.
MIT labs are focusing on four uncommon conditions in the first wave of RareNet projects: Rett syndrome, prion disease, disorders linked to SYNGAP1 mutations, and Sturge-Weber syndrome. The teams are working to develop novel therapies that can slow, halt, or reverse dysfunctions in the brain and nervous system.
These efforts will build new bridges to connect key stakeholders across the rare brain disorders community and disrupt conventional research approaches. “Rajeev and I are motivated to seed powerful collaborations between MIT researchers, clinicians, patients, and industry,” says Méndez. “Guoping Feng clearly understands our goal to create an environment where foundational studies can thrive and seamlessly move toward clinical impact.”
“Patient and caregiver experiences, and our foreseeable impact on their lives, will guide us and remain at the forefront of our work,” Feng adds. “For far too long the rare brain disorders community has been deprived of life-changing treatments — and, importantly, hope. RareNet gives us the opportunity to transform how we study these conditions and to do so at a moment when it’s needed more than ever.”
Which of those sentences are you most likely to remember a few minutes from now? If you guessed the second, you’re probably correct.
According to a new study from MIT cognitive scientists, sentences that stick in your mind longer are those that have distinctive meanings, making them stand out from sentences you’ve previously seen. They found that meaning, not any other trait, is the most important feature when it comes to memorability.
Greta Tuckute, a former graduate student in the Fedorenko lab. Photo: Caitlin Cunningham
“One might have thought that when you remember sentences, maybe it’s all about the visual features of the sentence, but we found that that was not the case. A big contribution of this paper is pinning down that it is the meaning-related space that makes sentences memorable,” says Greta Tuckute PhD ’25, who is now a research fellow at Harvard University’s Kempner Institute.
The findings support the hypothesis that sentences with distinctive meanings — like “Does olive oil work for tanning?” — are stored in brain space that is not cluttered with sentences that mean almost the same thing. Sentences with similar meanings end up densely packed together and are therefore more difficult to recognize confidently later on, the researchers believe.
“When you encode sentences that have a similar meaning, there’s feature overlap in that space. Therefore, a particular sentence you’ve encoded is not linked to a unique set of features, but rather to a whole bunch of features that may overlap with other sentences,” says Evelina Fedorenko, an MIT associate professor of brain and cognitive sciences (BCS), a member of MIT’s McGovern Institute for Brain Research, and the senior author of the study.
Tuckute and Thomas Clark, an MIT graduate student, are the lead authors of the paper, which appears in the Journal of Memory and Language. MIT graduate student Bryan Medina is also an author.
Distinctive sentences
What makes certain things more memorable than others is a longstanding question in cognitive science and neuroscience. In a 2011 study, Aude Oliva, now a senior research scientist at MIT and MIT director of the MIT-IBM Watson AI Lab, showed that not all items are created equal: Some types of images are much easier to remember than others, and people are remarkably consistent in what images they remember best.
In that study, Oliva and her colleagues found that, in general, images with people in them are the most memorable, followed by images of human-scale space and close-ups of objects. Least memorable are natural landscapes.
As a follow-up to that study, Fedorenko and Oliva, along with Ted Gibson, another faculty member in BCS, teamed up to determine if words also vary in their memorability. In a study published earlier this year, co-led by Tuckute and Kyle Mahowald, a former PhD student in BCS, the researchers found that the most memorable words are those that have the most distinctive meanings.
Words are categorized as being more distinctive if they have a single meaning, and few or no synonyms — for example, words like “pineapple” or “avalanche” which were found to be very memorable. On the other hand, words that can have multiple meanings, such as “light,” or words that have many synonyms, like “happy,” were more difficult for people to recognize accurately.
In the new study, the researchers expanded their scope to analyze the memorability of sentences. Just like words, some sentences have very distinctive meanings, while others communicate similar information in slightly different ways.
To do the study, the researchers assembled a collection of 2,500 sentences drawn from publicly available databases that compile text from novels, news articles, movie dialogues, and other sources. Each sentence that they chose contained exactly six words.
The researchers then presented a random selection of about 1,000 of these sentences to each study participant, including repeats of some sentences. Each of the 500 participants in the study was asked to press a button when they saw a sentence that they remembered seeing earlier.
The most memorable sentences — the ones where participants accurately and quickly indicated that they had seen them before — included strings such as “Homer Simpson is hungry, very hungry,” and “These mosquitoes are — well, guinea pigs.”
Those memorable sentences overlapped significantly with sentences that were determined as having distinctive meanings as estimated through the high-dimensional vector space of a large language model (LLM) known as Sentence BERT. That model is able to generate sentence-level representations of sentences, which can be used for tasks like judging meaning similarity between sentences. This model provided researchers with a distinctness score for each sentence based on its semantic similarity to other sentences.
The researchers also evaluated the sentences using a model that predicts memorability based on the average memorability of the individual words in the sentence. This model performed fairly well at predicting overall sentence memorability, but not as well as Sentence BERT. This suggests that the meaning of a sentence as a whole — above and beyond the contributions from individual words — determines how memorable it will be, the researchers say.
Noisy memories
While cognitive scientists have long hypothesized that the brain’s memory banks have a limited capacity, the findings of the new study support an alternative hypothesis that would help to explain how the brain can continue forming new memories without losing old ones.
This alternative, known as the noisy representation hypothesis, says that when the brain encodes a new memory, be it an image, a word, or a sentence, it is represented in a noisy way — that is, this representation is not identical to the stimulus, and some information is lost. For example, for an image, you may not encode the exact viewing angle at which an object is shown, and for a sentence, you may not remember the exact construction used.
Under this theory, a new sentence would be encoded in a similar part of the memory space as sentences that carry a similar meanings, whether they were encountered recently or sometime across a lifetime of language experience. This jumbling of similar meanings together increases the amount of noise and can make it much harder, later on, to remember the exact sentence you have seen before.
“The representation is gradually going to accumulate some noise. As a result, when you see an image or a sentence for a second time, your accuracy at judging whether you’ve seen it before will be affected, and it’ll be less than 100 percent in most cases,” Clark says.
However, if a sentence has a unique meaning that is encoded in a less densely crowded space, it will be easier to pick out later on.
“Your memory may still be noisy, but your ability to make judgments based on the representations is less affected by that noise because the representation is so distinctive to begin with,” Clark says.
The researchers now plan to study whether other features of sentences, such as more vivid and descriptive language, might also contribute to making them more memorable, and how the language system may interact with the hippocampal memory structures during the encoding and retrieval of memories.
The research was funded, in part, by the National Institutes of Health, the McGovern Institute, the Department of Brain and Cognitive Sciences, the Simons Center for the Social Brain, and the MIT Quest Initiative for Intelligence.
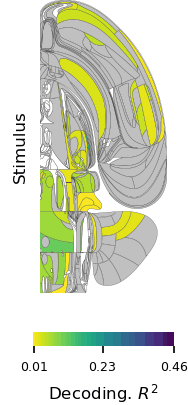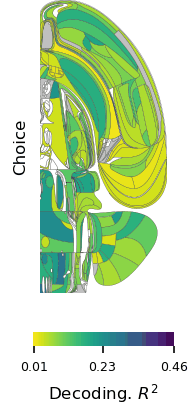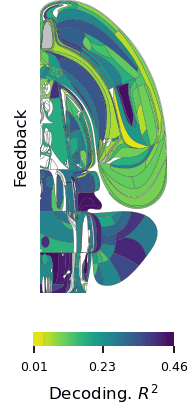
The first comprehensive map of mouse brain activity has been unveiled by a large international collaboration of neuroscientists. Researchers from the International Brain Laboratory (IBL), including McGovern Investigator Ila Fiete, published their findings today in two papers in Nature, revealing insights into how decision-making unfolds across the entire brain in mice at single-cell resolution. This brain-wide activity map challenges the traditional hierarchical view of information processing in the brain and shows that decision-making is distributed across many regions in a highly coordinated way.
“This is the first time anyone has produced a full, brain-wide map of the activity of single neurons during decision-making,” explains Co-Founder of IBL Alexandre Pouget. “The scale is unprecedented as we recorded from over half a million neurons across mice in 12 labs, covering 279 brain areas, which together represent 95% of the mouse brain volume. The decision-making activity, and particularly reward, lit up the brain like a Christmas tree,” adds Pouget, who is also a Group Leader at the University of Geneva.
Brain-wide map showing 75,000 analyzed neurons lighting up during different stages of decision-making. At the beginning of the trial, the activity is quiet. Then it builds up in the visual areas at the back of the brain, followed by a rise in activity spreading across the brain as evidence accumulates towards a decision. Next, motor areas light up as there is movement onset and finally there is a spike in activity everywhere in the brain as the animal is rewarded.
Modeling decision-making
The brain map was made possible by a major international collaboration of neuroscientists from multiple universities, including MIT. Researchers across 12 labs used state-of-the-art silicon electrodes, called Neuropixels probes, for simultaneous neural recordings to measure brain activity while mice were carrying out a decision-making task.
McGovern Associate Investigator Ila Fiete. Photo: Caitlin Cunningham
“Participating in the International Brain Laboratory has added new ways for our group to contribute to science,” says Fiete, who is also a professor of brain and cognitive sciences director of the K. Lisa Yang ICoN Center at MIT. “Our lab has helped standardize methods to analyze and generate robust conclusions from data. As computational neuroscientists interested in building models of how the brain works, access to brainwide recordings is incredible: the traditional approach of recording from one or a few brain areas limited our ability to build and test theories, resulting in fragmented models. Now we have the delightful but formidable task to make sense of how all parts of the brain coordinate to perform a behavior. Surprisingly, having a full view of the brain leads to simplifications in the models of decision making.”
The labs collected data from mice performing a decision-making task with sensory, motor, and cognitive components. In the task, a mouse sits in front of a screen and a light appears on the left or right side. If the mouse then responds by moving a small wheel in the correct direction, it receives a reward.
In some trials, the light is so faint that the animal must guess which way to turn the wheel, for which it can use prior knowledge: the light tends to appear more frequently on one side for a number of trials, before the high-frequency side switches. Well-trained mice learn to use this information to help them make correct guesses. These challenging trials therefore allowed the researchers to study how prior expectations influence perception and decision-making.
Brain-wide results
The first paper, “A brain-wide map of neural activity during complex behaviour,” showed that decision-making signals are surprisingly distributed across the brain, not localized to specific regions. This adds brain-wide evidence to a growing number of studies that challenge the traditional hierarchical model of brain function and emphasizes that there is constant communication across brain areas during decision-making, movement onset, and even reward. This means that neuroscientists will need to take a more holistic, brain-wide approach when studying complex behaviors in future.
Flat maps of the mouse brain showing which areas have significant changes in activity during each of three task intervals. Credit: Michael Schartner & International Brain Laboratory
“The unprecedented breadth of our recordings pulls back the curtain on how the entire brain performs the whole arc of sensory processing, cognitive decision-making, and movement generation,” says Fiete. “Structuring a collaboration that collects a large standardized dataset which single labs could not assemble is a revolutionary new direction for systems neuroscience, initiating the field into the hyper-collaborative mode that has contributed to leaps forward in particle physics and human genetics. Beyond our own conclusions, the dataset and associated technologies, which were released much earlier as part of the IBL mission, have already become a massively used resource for the entire neuroscience community.”
The second paper, “Brain-wide representations of prior information,” showed that prior expectations, our beliefs about what is likely to happen based on our recent experience, are encoded throughout the brain. Surprisingly, these expectations are not only found in cognitive areas, but also brain areas that process sensory information and control actions. For example, expectations are even encoded in early sensory areas such as the thalamus, the brain’s first relay for visual input from the eye. This supports the view that the brain acts as a prediction machine, but with expectations encoded across multiple brain structures playing a central role in guiding behavior responses. These findings could have implications for understanding conditions such as schizophrenia and autism, which are thought to be caused by differences in the way expectations are updated in the brain.
“Much remains to be unpacked: if it is possible to find a signal in a brain area, does it mean that this area is generating the signal, or simply reflecting a signal generated somewhere else? How strongly is our perception of the world is shaped by our expectations? Now we can generate some quantitative answers and begin the next phase experiments to learn about the origins of the expectation signals by intervening to modulate their activity,” says Fiete.
Looking ahead, the team at IBL plan to expand beyond their initial focus on decision-making to explore a broader range of neuroscience questions. With renewed funding in hand, IBL aims to expand its research scope and continue to support large-scale, standardized experiments.
New model of collaborative neuroscience
Officially launched in 2017, IBL introduced a new model of collaboration in neuroscience that uses a standardized set of tools and data processing pipelines shared across multiple labs, enabling the collection of massive datasets while ensuring data alignment and reproducibility. This approach to democratize and accelerate science draws inspiration from large-scale collaborations in physics and biology, such as CERN and the Human Genome Project.
All data from these studies, along with detailed specifications of the tools and protocols used for data collection, are openly accessible to the global scientific community for further analysis and research. Summaries of these resources can be viewed and downloaded on the IBL website under the sections: Data, Tools, Protocols.
This research was supported by grants from Wellcome (209558 and 216324), the Simons Foundation, The National Institutes of Health (NIH U19NS12371601), the National Science Foundation (NSF 1707398), the Gatsby Charitable Foundation (GAT3708), andby the Max Planck Society and the Humboldt Foundation.
The question of how we know ourselves might seem the subject of philosophers, but it is just as much a matter of biology. As modern neuroscientists obtain an increasingly sophisticated understanding of how the brain generates emotions, responds to the external world, and learns from experience, some researchers are returning to a central question: How do we know our experiences, emotions, and physical sensations belong to us?
Curiosity about how the brain generates our sense of self has been a driving force for the research of McGovern Investigator Fan Wang. Following that curiosity has drawn Wang into diverse studies, exploring the origins of pain and the mechanisms we use to control our movements.
“We cannot pinpoint a set of active neurons and say that’s the sense of self. That still remains a mystery,” says Wang, who is also a professor of brain and cognitive sciences and co-director of the K. Lisa Yang and Hock E. Tan Center for Molecular Therapeutics at MIT. But she and other neuroscientists are drilling down into different functions of the brain that together might generate our awareness of ourselves.
McGovern Investigator Fan Wang (right) with research scientist Vincent Prevosto, who studies brain regions implicated in whisker movement. Photo: Steph Stevens
Wang, who teaches the undergraduate course, “Neurobiology of Self,” explains that there are lots of ways to think about our sense of self, which are probably deeply integrated in the brain. Some are mostly about our physical bodies: How do we experience touch? How do we understand
where we are in space, or recognize the boundary between ourselves and rest of the world? Some consider more internal sensations, like how we experience pain or hunger. Emotion is also key to our sense of self: How do we know that anger or joy are our own, and why do these states change the way our bodies feel?
Wang can trace her initial interest in the brain’s sense of self to work she did as a graduate student in Richard Axel’s lab at Columbia University. The lab had identified receptors expressed by sensory neurons in the nose that detect odorous substances. Wang and others discovered the pathways that information about these smells takes to the brain, and how the brain distinguishes one smell from another.
Who is the “knower” of this information? “The answer,” Wang says, “is ‘I’ or ‘me.’ But understanding where I get the sense of self and how that is constructed, is what drives me to do neuroscience.”
Mechanisms of movement
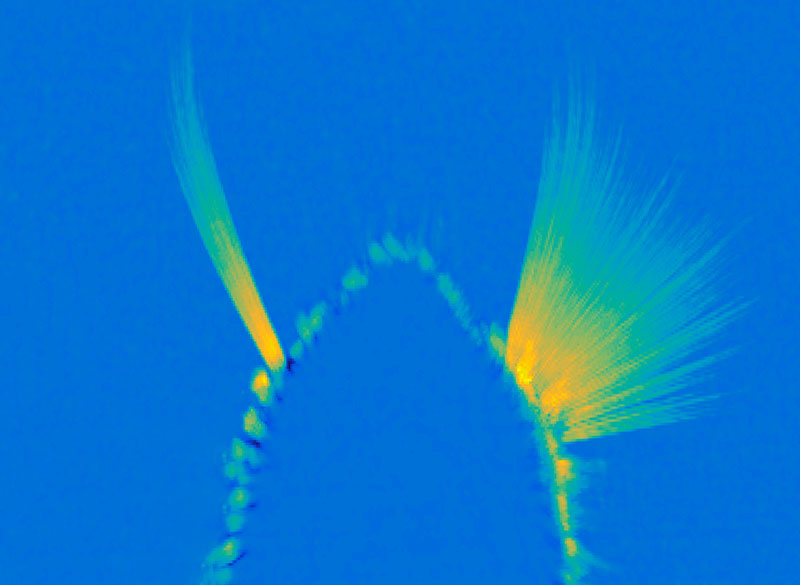
In her lab at the McGovern Institute, Wang is studying how the brain controls the body’s movements, which she sees as closely tied to the awareness of our physical selves. “The reason I think I am in my body is because I can control my movement. I generate the movement. I cannot control your movement,” says Wang. “Volitional movement gives us a sense of agency, and this sense of agency resembles the sense of self.” For the mice that the group studies, one crucial type of movement comes from the whiskers, which the animals depend on as they explore their environments. Wang’s group has traced the neural circuity that controls whiskers’ rhythmic back-and-forth, which is initiated in the brainstem, where many of the body’s most vital functions are controlled. Wang describes the simple circuit as an oscillator, or a self-generated loop.
A maximum projection image showing tracked whiskers on the mouse muzzle. The right (control) side shows the back-and-forth rhythmic sweeping of the whiskers, while the experimental side where the whisking oscillator neurons are silenced, the whiskers move very little. Image: Wang Lab
Once it’s started, “the movement can go on unless some other signals stop it,” she says. The movement the circuit generates is simple but voluntary, and can be fine-tuned based on the sensory feedback the whiskers relay back to the brain. They’ve also been investigating how mice move the larynx to generate the squeaks and calls they use to communicate. These intentional movements must be coordinated with the ongoing cycles of respiration since we produce normal sounds only during expiration. Wang’s team has found neurons in the brainstem that generate vocalization-specific movements, and also discovered how respiration-controlling neural circuits can override them, ensuring that breathing is prioritized.
Wang says understanding the circuitry that controls these simple movements sets the stage for figuring out how the brain modifies activity in those circuits to create more complex, intentional movements. “That brings me closer to understanding where this volition is generated — and closer to this sense of self,” she says.
Emotional pain
Still, she knows that volitional movements — even those generated in response to perceptions of the environment — do not, on their own, define a sense of self. As a counterexample, she looks to self-driving cars: “There’s sensory information coming into the central computer, which then generates a motor output — where to drive, where to turn, where to stop. But none of us think a Waymo taxi has a sense of self.”
Wang says when she pondered the ways in which AI-powered cars lack a sense of self, she began thinking about emotions and pain. “If the self-driving Waymo crashes, it will not feel pain,” she says. “But if we hurt ourselves, we will feel pain. And we will hate that, and then we’ll learn.” So her lab is also exploring how the nervous system generates pain perception, including the emotional response that it evokes.
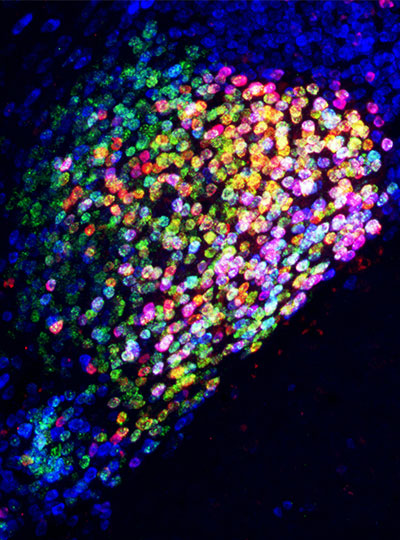
Ensembles of neurons in the amygdala activated by general anesthesia. Image: Fan Wang
In both humans and mice, pain causes emotional suffering that can be recognized and measured through changes in body functions like heart rate and blood pressure. With funding from the K. Lisa Yang Brain-Body Center at MIT, Wang’s lab is carefully tracking these involuntary, or autonomic, functions to gain a more complete understanding of pain’s emotional impact. This approach has helped clarify the role of pain-suppressing neurons in the brain’s amygdala — an important emotion-processing center — that Wang’s team discovered in 2020. When researchers selectively activate those cells in mice, the animals’ behavior makes it clear that the neurons are suppressing pain. Now, the group has learned that activating these neurons suppresses the autonomic response to pain.
Wang says there’s hope that modulating pain’s emotional response might be a way to treat chronic pain in patients. She explains that some patients with damage to another one of the brain’s emotional centers, the cingulate cortex, feel painful stimuli, but experience them as merely intense sensations. That suggests that it might be possible to modulate the emotional response to pain to eliminate patients’ suffering, without blocking the protective information that pain can provide.
The team has also been focusing on another set of anesthesia-activated neurons, which they have found suppress anxiety. When anxiety-suppressing neurons are activated in mice, the animals’ heart rates slow and they become more willing to explore bright, open spaces. Another anxiety-associated measure — heart rate variability — increases. Wang explains that this change is particularly significant: “If you have persistent low heart rate variability, especially in veterans, that is a very good predictor for anxiety developing into depression in the future,” she says.
The team’s findings, which suggest that changes in autonomic functions may themselves relieve anxiety, point toward potential new targets for anti-anxiety therapies. And by highlighting the connection between emotion and bodily responses, they offer more clues about our sense of self. “These neurons are now changing some high-level concept about anxiety,” Wang points out.
That link between emotion and body seems to Wang to be key to the sense of self. The big questions remain unanswered, but that simply stokes her curiosity. “I can be aware of my bodily responses: I am aware of ‘I am anxious’ or ‘I am in pain.’ I can see the pathways from which stimuli go into these nervous systems and come back down to the body and control the response. But I still don’t know who is the person — the knower,” she says. “I haven’t found it, so I’m going to keep looking.”
Anikeeva, the Matoula S. Salapatas Professor in Materials Science and Engineering at MIT, works at the intersection of materials science, electronics, and neurobiology to improve our understanding of brain-body communication. She is head of MIT’s Materials Science and Engineering Department, and is also a professor of brain and cognitive sciences, director of the K. Lisa Yang Brain-Body Center, and associate director of the Research Laboratory of Electronics. Anikeeva’s lab has developed ultrathin, flexible fibers that probe the flow of information between the brain and peripheral organs in the body. Her ultimate goal is to develop novel technologies to achieve healthy minds in healthy bodies.
The Blavatnik National Awards for Young Scientists is the largest unrestricted scientific prize offered to America’s most promising, faculty-level scientific researchers under 42. The 2024 Blavatnik National Awards received 331 nominations from 172 institutions in 43 US states and selected three women scientists as laureates (Cigall Kadoch, Dana Farber Cancer Institute; Markita del Carpio Landry, UC Berkeley; and Britney Schmidt, Cornell University). An additional 15 finalists, including two from MIT: Anikeeva and Yogesh Surendranath will also receive monetary prizes.
“On behalf of the Blavatnik Family Foundation, I congratulate this year’s outstanding laureates and finalists for their exceptional research. They are among the preeminent leaders of the next generation of scientific innovation and discovery,” said Len Blavatnik, founder of Access Industries and the Blavatnik Family Foundation and a member of the President’s Council of The New York Academy of Sciences.
The Blavatnik National Awards for Young Scientists will celebrate the 2024 laureates and finalists in a gala ceremony on October 1, 2024, at the American Museum of Natural History in New York.