Even before MIT sent out its first official announcement about the COVID-19 crisis, I had already asked permission from my supervisor and taken my computer home so that I could start working from home.
My first and foremost concern was my family and friends. I was born and brought up in India, and then immigrated to Canada, so I have a big and wonderful family spread across both those countries. These countries had a lower number of COVID-19 cases at the time, but I could see what would be coming their way. I was anxious, very anxious. In India, my dad being an anesthetist could be exposed while working in the hospital. In Canada, my uncle who is a physician could be exposed, and on top of that he lives in the same house as my grandparents who are even more vulnerable due to their age. I knew I had to do something.
We started having regular video calls as a family. My mom even led daily online yoga sessions, and the discussions that followed those sessions ensured that we didn’t feel lonely and gave us a sense of purpose. Together, we looked at the statistics in the data from China and Italy, and learned that we needed to flatten the curve due to the lack of medical resources required to meet the need of the hour. We could foresee that more infections would lead to more patients, thus raising the demand for medical resources beyond the amount we had available.
We had several discussions around developing products for helping medical professionals and the general public during this pandemic.
We learned that since no government has enough resources to cope at the time of pandemics, we have to be innovative in trying to make the best use of the limited resources available to us.
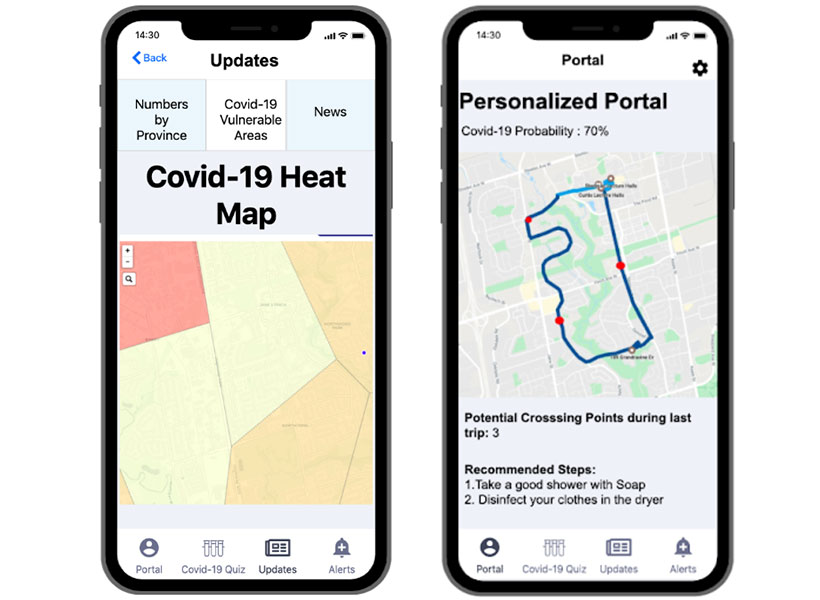
Through our discussions and experiences of some of us in the field, we came to the conclusion that the only way to effectively fight COVID-19 is prevention at source. Hence, we started working on a mobile app that uses AI and advanced data analytics to trace contact, determine the risk of infection, and thereby suggest precautions. Luckily we have engineers and computer scientists in our family (my own background is in electrical engineering), so it was easy for us to divide the work. In our prototype, when people sign-up, they are asked to fill out a short self-assessment form that can be used to identify any symptoms of COVID-19. This data is then used to predict vulnerable areas and to give recommendations to people who might have taken a certain route as shown below.
Sharma’s mobile app showing heatmap of the vulnerable areas in a locality in Toronto, ON (left) and personalized recommendations based on the most recent route taken by an individual (right).
We ended up submitting our proposal and prototype to the COVID-19 challenge launched by Vale (a global mining company) and the winners will be announced in May.
Personally, to be completely honest, I had my times when I broke down due to everything that was going on in the world around me. It’s not easy to see people dying, and losing jobs. My way of staying strong was to make sure that I was doing my best to contribute.
I have set up a beautiful home office for myself and I am focusing on my PhD research, being grateful that I can still continue to do it from home. I have also restarted the joint MIT-Harvard computational neuroscience journal club meetings online, so that members can get access to this wonderful community once again! It was amazing to see from a poll we conducted that 92% of the members of the club wanted the meetings to be re-started online.
These times are unprecedented for my generation, my mom’s generation and even for my grandmother’s generation. I have never seen the world come together in a way I have seen during this pandemic. The kind of response we have seen from our societies and governments across the globe shows that we can make intelligent decisions for the collective good of humanity. For once, we’re all on the same side!
Sugandha (Su) Sharma is a graduate student in the labs of Ila Fiete and Josh Tenenbaum. When she’s not developing a mobile app to fight COVID-19, Su explores the computational and theoretical principles underlying higher level cognition and intelligence in the human brain.
Michal De-Medonsa, technical associate and manager of the Jazayeri lab, created a large wood mosaic for her lab. We asked Michal to tell us a bit about the mosaic, her inspiration, and how in the world she found the time to create such an exquisitely detailed piece of art.
______
Jazayeri lab manager Michal De-Medonsa holds her wood mosaic entitled “JazLab.” Photo: Caitlin Cunningham
Describe this piece of art for us.
To make a piece this big (63″ x 15″), I needed several boards of padauk wood. I could have just etched each board as a whole unit and glued the 13 or so boards to each other, but I didn’t like the aesthetic. The grain and color within each board would look beautiful, but the line between each board would become obvious, segmented, and jarring when contrasted with the uniformity within each board. Instead, I cut out about 18 separate squares out of each board, shuffled all 217 pieces around, and glued them to one another in a mosaic style with a larger pattern (inspired by my grandfather’s work in granite mosaics).
What does this mosaic mean to you?
Once every piece was shuffled, the lines between single squares were certainly visible, but as a feature, were far less salient than had the full boards been glued to one another. As I was working on the piece, I was thinking about how the same concept holds true in society. Even if there is diversity within a larger piece (an institution, for example), there is a tendency for groups to form within the larger piece (like a full board), diversity becomes separated. This isn’t a criticism of any institution, it is human nature to form in-groups. It’s subconscious (so perhaps the criticism is that we, as a society, don’t give that behavior enough thought and try to ameliorate our reflex to group with those who are “like us”). The grain of the wood is uniform, oriented in the same direction, the two different cutting patterns create a larger pattern within the piece, and there are smaller patterns between and within single pieces. I love creating and finding patterns in my art (and life). Alfred North Whitehead wrote that “understanding is the apperception of pattern as such.” True, I believe, in science, art, and the humanities. What a great goal – to understand.
Tell us about the name of this piece.
Every large piece I make is inspired by the people I make it for, and is therefore named after them. This piece is called JazLab. Having lived around the world, and being a descendant of a nomadic people, I don’t consider any one place home, but am inspired by every place I’ve lived. In all of my work, you can see elements of my Jewish heritage, antiquity, the Middle East, Africa, and now MIT.
How has MIT influenced your art?
MIT has influenced me in the most obvious way MIT could influence anyone – technology. Before this series, I made very small versions of this type of work, designing everything on a piece of paper with a pencil and a ruler, and making every cut by hand. Each of those small squares would take ~2 hours (depending on the design), and I was limited to softer woods.
Since coming to MIT, I learned that I had access to the Hobby Shop with a huge array of power tools and software. I began designing my patterns on the computer and used power tools to make the cuts. I actually struggled a lot with using the tech – not because it was hard (which, it really is when you just start out), but rather because it felt like I was somehow “cheating.” How is this still art? And although this is something I still think about often, I’ve tried to look at it in this way: every generation, in their time, used the most advanced technology. The beauty and value of the piece doesn’t come from how many bruises, cuts, and blisters your machinery gave you, or whether you scraped the wood out with your nails, but rather, once you were given a tool, what did you decide to do with it? My pieces still have a huge hand-on-material work, but I am working on accepting that using technology in no way devalues the work.
Given your busy schedule with the Jazayeri lab, how did you find the time to create this piece of art?
I took advantage of any free hour I could. Two days out of the week, the hobby shop is open until 9pm, and I would additionally go every Saturday. For the parts that didn’t require the shop (adjusting each piece individually with a carving knife, assembling them, even most of the glueing) I would just work at home – often very late into the night.
______
JazLab is on display in the Jazayeri lab in MIT Bldg 46.
Visual art has found many ways of representing objects, from the ornate Baroque period to modernist simplicity. Artificial visual systems are somewhat analogous: from relatively simple beginnings inspired by key regions in the visual cortex, recent advances in performance have seen increasing complexity.
“Our overall goal has been to build an accurate, engineering-level model of the visual system, to ‘reverse engineer’ visual intelligence,” explains James DiCarlo, the head of MIT’s Department of Brain and Cognitive Sciences, an investigator in the McGovern Institute for Brain Research and the Center for Brains, Minds, and Machines (CBMM). “But very high-performing ANNs have started to drift away from brain architecture, with complex branching architectures that have no clear parallel in the brain.”
A new model from the DiCarlo lab has re-imposed a brain-like architecture on an object recognition network. The result is a shallow-network architecture with surprisingly high performance, indicating that we can simplify deeper– and more baroque– networks yet retain high performance in artificial learning systems.
“We’ve made two major advances,” explains graduate student Martin Schrimpf, who led the work with Jonas Kubilius at CBMM. “We’ve found a way of checking how well models match the brain, called Brain-Score, and developed a model, CORnet, that moves artificial object recognition, as well as machine learning architectures, forward.”
DiCarlo lab graduate student Martin Schrimpf in the lab. Photo: Kris Brewer
Back to the brain
Deep convolutional artificial neural networks were initially inspired by brain anatomy, and are the leading models in artificial object recognition. Training these feedforward systems on recognizing objects in ImageNet, a large database of images, has allowed performance of ANNs to vastly improve, but at the same time networks have literally branched out, become increasingly complex with hundreds of layers. In contrast, the visual ventral stream, a series of cortical brain regions that unpack object identity, contains a relatively minuscule four key regions. In addition, ANNs are entirely feedforward, while the primate cortical visual system has densely interconnected wiring, in other words, recurrent connectivity. While primate-like object recognition capabilities can be captured through feedforward-only networks, recurrent wiring in the brain has long been suspected, and recently shown in two DiCarlo lab papers led by Kar and Tang respectively, to be important.
DiCarlo and colleagues have now developed CORnet-S, inspired by very complex, state-of-the-art neural networks. CORnet-S has four computational areas, analogous to cortical visual areas (V1, V2, V4, and IT). In addition, CORnet-S contains repeated, or recurrent, connections.
“We really pre-defined layers in the ANN, defining V1, V2, and so on, and introduced feedback and repeated connections” explains Schrimpf. “As a result, we ended up with fewer layers, and less ‘dead space’ that cannot be mapped to the brain. In short, a simpler network.”
Keeping score
To optimize the system, the researchers incorporated quantitative assessment through a new system, Brain-Score.
“Until now, we’ve needed to qualitatively eyeball model performance relative to the brain,” says Schrimpf. “Brain-Score allows us to actually quantitatively evaluate and benchmark models.”
They found that CORnet-S ranks highly on Brain-Score, and is the best performer of all shallow ANNs. Indeed, the system, shallow as it is, rivals the complex, ultra-deep ANNs that currently perform at the highest level.
CORnet was also benchmarked against human performance. To test, for example, whether the system can predict human behavior, 1,472 humans were shown images for 100ms and then asked to identify objects in them. CORnet-S was able to predict the general accuracy of humans to make calls about what they had briefly glimpsed (bear vs. dog etc.). Indeed, CORnet-S is able to predict the behavior, as well as the neural dynamics, of the visual ventral stream, indicating that it is modeling primate-like behavior.
“We thought we’d lose performance by going to a wide, shallow network, but with recurrence, we hardly lost any,” says Schrimpf, “the message for machine learning more broadly, is you can get away without really deep networks.”
Such models of brain processing have benefits for both neuroscience and artificial systems, helping us to understand the elements of image processing by the brain. Neuroscience in turn informs us that features such as recurrence, can be used to improve performance in shallow networks, an important message for artificial intelligence systems more broadly.
“There are clear advantages to the high performing, complex deep networks,” explains DiCarlo, “but it’s possible to rein the network in, using the elegance of the primate brain as a model, and we think this will ultimately lead to other kinds of advantages.”
When your mother calls your name, you know it’s her voice — no matter the volume, even over a poor cell phone connection. And when you see her face, you know it’s hers — if she is far away, if the lighting is poor, or if you are on a bad FaceTime call. This robustness to variation is a hallmark of human perception. On the other hand, we are susceptible to illusions: We might fail to distinguish between sounds or images that are, in fact, different. Scientists have explained many of these illusions, but we lack a full understanding of the invariances in our auditory and visual systems.
Deep neural networks also have performed speech recognition and image classification tasks with impressive robustness to variations in the auditory or visual stimuli. But are the invariances learned by these models similar to the invariances learned by human perceptual systems? A group of MIT researchers has discovered that they are different. They presented their findings yesterday at the 2019 Conference on Neural Information Processing Systems.
The researchers made a novel generalization of a classical concept: “metamers” — physically distinct stimuli that generate the same perceptual effect. The most famous examples of metamer stimuli arise because most people have three different types of cones in their retinae, which are responsible for color vision. The perceived color of any single wavelength of light can be matched exactly by a particular combination of three lights of different colors — for example, red, green, and blue lights. Nineteenth-century scientists inferred from this observation that humans have three different types of bright-light detectors in our eyes. This is the basis for electronic color displays on all of the screens we stare at every day. Another example in the visual system is that when we fix our gaze on an object, we may perceive surrounding visual scenes that differ at the periphery as identical. In the auditory domain, something analogous can be observed. For example, the “textural” sound of two swarms of insects might be indistinguishable, despite differing in the acoustic details that compose them, because they have similar aggregate statistical properties. In each case, the metamers provide insight into the mechanisms of perception, and constrain models of the human visual or auditory systems.
In the current work, the researchers randomly chose natural images and sound clips of spoken words from standard databases, and then synthesized sounds and images so that deep neural networks would sort them into the same classes as their natural counterparts. That is, they generated physically distinct stimuli that are classified identically by models, rather than by humans. This is a new way to think about metamers, generalizing the concept to swap the role of computer models for human perceivers. They therefore called these synthesized stimuli “model metamers” of the paired natural stimuli. The researchers then tested whether humans could identify the words and images.
“Participants heard a short segment of speech and had to identify from a list of words which word was in the middle of the clip. For the natural audio this task is easy, but for many of the model metamers humans had a hard time recognizing the sound,” explains first-author Jenelle Feather, a graduate student in the MIT Department of Brain and Cognitive Sciences (BCS) and a member of the Center for Brains, Minds, and Machines (CBMM). That is, humans would not put the synthetic stimuli in the same class as the spoken word “bird” or the image of a bird. In fact, model metamers generated to match the responses of the deepest layers of the model were generally unrecognizable as words or images by human subjects.
Josh McDermott, associate professor in BCS and investigator in CBMM, makes the following case: “The basic logic is that if we have a good model of human perception, say of speech recognition, then if we pick two sounds that the model says are the same and present these two sounds to a human listener, that human should also say that the two sounds are the same. If the human listener instead perceives the stimuli to be different, this is a clear indication that the representations in our model do not match those of human perception.”
Joining Feather and McDermott on the paper are Alex Durango, a post-baccalaureate student, and Ray Gonzalez, a research assistant, both in BCS.
There is another type of failure of deep networks that has received a lot of attention in the media: adversarial examples (see, for example, “Why did my classifier just mistake a turtle for a rifle?“). These are stimuli that appear similar to humans but are misclassified by a model network (by design — they are constructed to be misclassified). They are complementary to the stimuli generated by Feather’s group, which sound or appear different to humans but are designed to be co-classified by the model network. The vulnerabilities of model networks exposed to adversarial attacks are well-known — face-recognition software might mistake identities; automated vehicles might not recognize pedestrians.
The importance of this work lies in improving models of perception beyond deep networks. Although the standard adversarial examples indicate differences between deep networks and human perceptual systems, the new stimuli generated by the McDermott group arguably represent a more fundamental model failure — they show that generic examples of stimuli classified as the same by a deep network produce wildly different percepts for humans.
The team also figured out ways to modify the model networks to yield metamers that were more plausible sounds and images to humans. As McDermott says, “This gives us hope that we may be able to eventually develop models that pass the metamer test and better capture human invariances.”
“Model metamers demonstrate a significant failure of present-day neural networks to match the invariances in the human visual and auditory systems,” says Feather, “We hope that this work will provide a useful behavioral measuring stick to improve model representations and create better models of human sensory systems.”
Malinda McPherson is a graduate student in Josh McDermott‘s lab, studying how people hear pitch (how high or low a sound is) in both speech and music.
To test the extent to which human audition varies across cultures, McPherson travels with the McDermott lab to Bolivia to study the Tsimane’ — a native Amazonian society with minimal exposure to Western culture.
Their most recent study, published in the journal Current Biology, found a striking variation in perception of musical pitch across cultures.
In this Q&A, we ask McPherson what motivates her research and to describe some of the challenges she has experienced working in the Bolivian rainforest.
What are you working on now?
Right now, I’m particularly excited about a project that involves working with children; we are trying to better understand how the ability to hear pitch develops with age and experience. Difficulty hearing pitch is one of the first issues that most people with poor or corrected hearing find discouraging, so in addition to simply being an interesting basic component of audition, understanding how pitch perception develops may be useful in engineering assistive hearing devices.
How has your personal background inspired your research?
I’ve been an avid violist for over twenty years and still perform with the Chamber Music Society at MIT. When I was an undergraduate and deciding between a career as a professional musician and a career in science, I found a way to merge the two by working as a research assistant in a lab studying musical creativity. I worked in that lab for three years and was completely hooked. My musical training has definitely helped me design a few experiments!
What was your most challenging experience in Bolivia? Most rewarding?
The most challenging aspect of our fieldwork in Bolivia is sustaining our intensity over a period of 4-5 weeks. Every moment is precious, and the pace of work is both exhilarating and exhausting. Despite the long hours of work and travel (by canoe or by truck over very bumpy roads), it is an incredible privilege to meet with and to learn from the Tsimane’. I’ve been picking up some Tsimane’ phrases from the translators with whom we work, and can now have basic conversations with participants and make kids laugh, so that’s a lot of fun. A few children I met my first year greeted me by name when we went back this past year. That was a very special moment!
Translator Manuel Roca Moye (left) with Malinda McPherson and Josh McDermott in a fully loaded canoe. Photo: McDermott lab
What single scientific question do you hope to answer?
I’d be curious to figure out the overlaps and distinctions between how we perceive music versus speech, but I think one of the best aspects of science is that many of the important future questions haven’t been thought of yet!
People who are accustomed to listening to Western music, which is based on a system of notes organized in octaves, can usually perceive the similarity between notes that are same but played in different registers — say, high C and middle C. However, a longstanding question is whether this a universal phenomenon or one that has been ingrained by musical exposure.
This question has been hard to answer, in part because of the difficulty in finding people who have not been exposed to Western music. Now, a new study led by researchers from MIT and the Max Planck Institute for Empirical Aesthetics has found that unlike residents of the United States, people living in a remote area of the Bolivian rainforest usually do not perceive the similarities between two versions of the same note played at different registers (high or low).
“We’re finding that … there seems to be really striking variation in things that a lot of people would have presumed would be common across cultures and listeners,” says McDermott.
The findings suggest that although there is a natural mathematical relationship between the frequencies of every “C,” no matter what octave it’s played in, the brain only becomes attuned to those similarities after hearing music based on octaves, says Josh McDermott, an associate professor in MIT’s Department of Brain and Cognitive Sciences.
“It may well be that there is a biological predisposition to favor octave relationships, but it doesn’t seem to be realized unless you are exposed to music in an octave-based system,” says McDermott, who is also a member of MIT’s McGovern Institute for Brain Research and Center for Brains, Minds and Machines.
The study also found that members of the Bolivian tribe, known as the Tsimane’, and Westerners do have a very similar upper limit on the frequency of notes that they can accurately distinguish, suggesting that that aspect of pitch perception may be independent of musical experience and biologically determined.
McDermott is the senior author of the study, which appears in the journal Current Biology on Sept. 19. Nori Jacoby, a former MIT postdoc who is now a group leader at the Max Planck Institute for Empirical Aesthetics, is the paper’s lead author. Other authors are Eduardo Undurraga, an assistant professor at the Pontifical Catholic University of Chile; Malinda McPherson, a graduate student in the Harvard/MIT Program in Speech and Hearing Bioscience and Technology; Joaquin Valdes, a graduate student at the Pontifical Catholic University of Chile; and Tomas Ossandon, an assistant professor at the Pontifical Catholic University of Chile.
Octaves apart
Cross-cultural studies of how music is perceived can shed light on the interplay between biological constraints and cultural influences that shape human perception. McDermott’s lab has performed several such studies with the participation of Tsimane’ tribe members, who live in relative isolation from Western culture and have had little exposure to Western music.
In a study published in 2016, McDermott and his colleagues found that Westerners and Tsimane’ had different aesthetic reactions to chords, or combinations of notes. To Western ears, the combination of C and F# is very grating, but Tsimane’ listeners rated this chord just as likeable as other chords that Westerners would interpret as more pleasant, such as C and G.
Later, Jacoby and McDermott found that both Westerners and Tsimane’ are drawn to musical rhythms composed of simple integer ratios, but the ratios they favor are different, based on which rhythms are more common in the music they listen to.
In their new study, the researchers studied pitch perception using an experimental design in which they play a very simple tune, only two or three notes, and then ask the listener to sing it back. The notes that were played could come from any octave within the range of human hearing, but listeners sang their responses within their vocal range, usually restricted to a single octave.
Eduardo Undurraga, an assistant professor at the Pontifical Catholic University of Chile, runs a musical pitch perception experiment with a member of the Tsimane’ tribe of the Bolivian rainforest. Photo: Josh McDermott
Western listeners, especially those who were trained musicians, tended to reproduce the tune an exact number of octaves above or below what they heard, though they were not specifically instructed to do so. In Western music, the pitch of the same note doubles with each ascending octave, so tones with frequencies of 27.5 hertz, 55 hertz, 110 hertz, 220 hertz, and so on, are all heard as the note A.
Western listeners in the study, all of whom lived in New York or Boston, accurately reproduced sequences such as A-C-A, but in a different register, as though they hear the similarity of notes separated by octaves. However, the Tsimane’ did not.
“The relative pitch was preserved (between notes in the series), but the absolute pitch produced by the Tsimane’ didn’t have any relationship to the absolute pitch of the stimulus,” Jacoby says. “That’s consistent with the idea that perceptual similarity is something that we acquire from exposure to Western music, where the octave is structurally very important.”
The ability to reproduce the same note in different octaves may be honed by singing along with others whose natural registers are different, or singing along with an instrument being played in a different pitch range, Jacoby says.
Limits of perception
The study findings also shed light on the upper limits of pitch perception for humans. It has been known for a long time that Western listeners cannot accurately distinguish pitches above about 4,000 hertz, although they can still hear frequencies up to nearly 20,000 hertz. In a traditional 88-key piano, the highest note is about 4,100 hertz.
People have speculated that the piano was designed to go only that high because of a fundamental limit on pitch perception, but McDermott thought it could be possible that the opposite was true: That is, the limit was culturally influenced by the fact that few musical instruments produce frequencies higher than 4,000 hertz.
The researchers found that although Tsimane’ musical instruments usually have upper limits much lower than 4,000 hertz, Tsimane’ listeners could distinguish pitches very well up to about 4,000 hertz, as evidenced by accurate sung reproductions of those pitch intervals. Above that threshold, their perceptions broke down, very similarly to Western listeners.
“It looks almost exactly the same across groups, so we have some evidence for biological constraints on the limits of pitch,” Jacoby says.
One possible explanation for this limit is that once frequencies reach about 4,000 hertz, the firing rates of the neurons of our inner ear can’t keep up and we lose a critical cue with which to distinguish different frequencies.
“The new study contributes to the age-long debate about the interplays between culture and biological constraints in music,” says Daniel Pressnitzer, a senior research scientist at Paris Descartes University, who was not involved in the research. “This unique, precious, and extensive dataset demonstrates both striking similarities and unexpected differences in how Tsimane’ and Western listeners perceive or conceive musical pitch.”
Jacoby and McDermott now hope to expand their cross-cultural studies to other groups who have had little exposure to Western music, and to perform more detailed studies of pitch perception among the Tsimane’.
Such studies have already shown the value of including research participants other than the Western-educated, relatively wealthy college undergraduates who are the subjects of most academic studies on perception, McDermott says. These broader studies allow researchers to tease out different elements of perception that cannot be seen when examining only a single, homogenous group.
“We’re finding that there are some cross-cultural similarities, but there also seems to be really striking variation in things that a lot of people would have presumed would be common across cultures and listeners,” McDermott says. “These differences in experience can lead to dissociations of different aspects of perception, giving you clues to what the parts of the perceptual system are.”
The research was funded by the James S. McDonnell Foundation, the National Institutes of Health, and the Presidential Scholar in Society and Neuroscience Program at Columbia University.
The world is constantly bombarding our senses with information, but the ways in which our brain extracts meaning from this information remains elusive. How do neurons transform raw visual input into a mental representation of an object – like a chair or a dog?
In work published today in Nature Neuroscience, MIT neuroscientists have identified a brain circuit in mice that distills “high-dimensional” complex information about the environment into a simple abstract object in the brain.
“There are no degree markings in the external world, our current head direction has to be extracted, computed, and estimated by the brain,” explains Ila Fiete, an associate member of the McGovern Institute and senior author of the paper. “The approaches we used allowed us to demonstrate the emergence of a low-dimensional concept, essentially an abstract compass in the brain.”
This abstract compass, according to the researchers, is a one-dimensional ring that represents the current direction of the head relative to the external world.
Schooling fish
Trying to show that a data cloud has a simple shape, like a ring, is a bit like watching a school of fish. By tracking one or two sardines, you might not see a pattern. But if you could map all of the sardines, and transform the noisy dataset into points representing the positions of the whole school of sardines over time, and where each fish is relative to its neighbors, a pattern would emerge. This model would reveal a ring shape, a simple shape formed by the activity of hundreds of individual fish.
Fiete, who is also an associate professor in MIT’s Department of Brain and Cognitive Sciences, used a similar approach, called topological modeling, to transform the activity of large populations of noisy neurons into a data cloud the shape of a ring.
Simple and persistent ring
Previous work in fly brains revealed a physical ellipsoid ring of neurons representing changes in the direction of the fly’s head, and researchers suspected that such a system might also exist in mammals.
In this new mouse study, Fiete and her colleagues measured hours of neural activity from scores of neurons in the anterodorsal thalamic nucleus (ADN) – a region believed to play a role in spatial navigation – as the animals moved freely around their environment. They mapped how the neurons in the ADN circuit fired as the animal’s head changed direction.
Together these data points formed a cloud in the shape of a simple and persistent ring.
“In the absence of this ring,” Fiete explains, “we would be lost in the world.”
“This tells us a lot about how neural networks are organized in the brain,” explains Edvard Moser, Director of the Kavli Institute of Systems Neuroscience in Norway, who was not involved in the study. “Past data have indirectly pointed towards such a ring-like organization but only now has it been possible, with the right cell numbers and methods, to demonstrate it convincingly,” says Moser.
Their method for characterizing the shape of the data cloud allowed Fiete and colleagues to determine which variable the circuit was devoted to representing, and to decode this variable over time, using only the neural responses.
“The animal’s doing really complicated stuff,” explains Fiete, “but this circuit is devoted to integrating the animal’s speed along a one-dimensional compass that encodes head direction,” explains Fiete. “Without a manifold approach, which captures the whole state space, you wouldn’t know that this circuit of thousands of neurons is encoding only this one aspect of the complex behavior, and not encoding any other variables at the same time.”
Even during sleep, when the circuit is not being bombarded with external information, this circuit robustly traces out the same one-dimensional ring, as if dreaming of past head direction trajectories.
Further analysis revealed that the ring acts an attractor. If neurons stray off trajectory, they are drawn back to it, quickly correcting the system. This attractor property of the ring means that the representation of head direction in abstract space is reliably stable over time, a key requirement if we are to understand and maintain a stable sense of where our head is relative to the world around us.
“In the absence of this ring,” Fiete explains, “we would be lost in the world.”
Shaping the future
Fiete’s work provides a first glimpse into how complex sensory information is distilled into a simple concept in the mind, and how that representation autonomously corrects errors, making it exquisitely stable.
But the implications of this study go beyond coding of head direction.
“Similar organization is probably present for other cognitive functions so the paper is likely to inspire numerous new studies,” says Moser.
Fiete sees these analyses and related studies carried out by colleagues at the Norwegian University of Science and Technology, Princeton University, the Weitzman Institute, and elsewhere as fundamental to the future of neural decoding studies.
With this approach, she explains, it is possible to extract abstract representations of the mind from the brain, potentially even thoughts and dreams.
“We’ve found that the brain deconstructs and represents complex things in the world with simple shapes,” explains Fiete. “Manifold-level analysis can help us to find those shapes, and they almost certainly exist beyond head direction circuits.”
For decades, research has shown that our perception of the world is influenced by our expectations. These expectations, also called “prior beliefs,” help us make sense of what we are perceiving in the present, based on similar past experiences. Consider, for instance, how a shadow on a patient’s X-ray image, easily missed by a less experienced intern, jumps out at a seasoned physician. The physician’s prior experience helps her arrive at the most probable interpretation of a weak signal.
The process of combining prior knowledge with uncertain evidence is known as Bayesian integration and is believed to widely impact our perceptions, thoughts, and actions. Now, MIT neuroscientists have discovered distinctive brain signals that encode these prior beliefs. They have also found how the brain uses these signals to make judicious decisions in the face of uncertainty.
“How these beliefs come to influence brain activity and bias our perceptions was the question we wanted to answer,” says Mehrdad Jazayeri, the Robert A. Swanson Career Development Professor of Life Sciences, a member of MIT’s McGovern Institute for Brain Research, and the senior author of the study.
The researchers trained animals to perform a timing task in which they had to reproduce different time intervals. Performing this task is challenging because our sense of time is imperfect and can go too fast or too slow. However, when intervals are consistently within a fixed range, the best strategy is to bias responses toward the middle of the range. This is exactly what animals did. Moreover, recording from neurons in the frontal cortex revealed a simple mechanism for Bayesian integration: Prior experience warped the representation of time in the brain so that patterns of neural activity associated with different intervals were biased toward those that were within the expected range.
MIT postdoc Hansem Sohn, former postdoc Devika Narain, and graduate student Nicolas Meirhaeghe are the lead authors of the study, which appears in the July 15 issue of Neuron.
Ready, set, go
Statisticians have known for centuries that Bayesian integration is the optimal strategy for handling uncertain information. When we are uncertain about something, we automatically rely on our prior experiences to optimize behavior.
“If you can’t quite tell what something is, but from your prior experience you have some expectation of what it ought to be, then you will use that information to guide your judgment,” Jazayeri says. “We do this all the time.”
In this new study, Jazayeri and his team wanted to understand how the brain encodes prior beliefs, and put those beliefs to use in the control of behavior. To that end, the researchers trained animals to reproduce a time interval, using a task called “ready-set-go.” In this task, animals measure the time between two flashes of light (“ready” and “set”) and then generate a “go” signal by making a delayed response after the same amount of time has elapsed.
They trained the animals to perform this task in two contexts. In the “Short” scenario, intervals varied between 480 and 800 milliseconds, and in the “Long” context, intervals were between 800 and 1,200 milliseconds. At the beginning of the task, the animals were given the information about the context (via a visual cue), and therefore knew to expect intervals from either the shorter or longer range.
Jazayeri had previously shown that humans performing this task tend to bias their responses toward the middle of the range. Here, they found that animals do the same. For example, if animals believed the interval would be short, and were given an interval of 800 milliseconds, the interval they produced was a little shorter than 800 milliseconds. Conversely, if they believed it would be longer, and were given the same 800-millisecond interval, they produced an interval a bit longer than 800 milliseconds.
“Trials that were identical in almost every possible way, except the animal’s belief led to different behaviors,” Jazayeri says. “That was compelling experimental evidence that the animal is relying on its own belief.”
Once they had established that the animals relied on their prior beliefs, the researchers set out to find how the brain encodes prior beliefs to guide behavior. They recorded activity from about 1,400 neurons in a region of the frontal cortex, which they have previously shown is involved in timing.
During the “ready-set” epoch, the activity profile of each neuron evolved in its own way, and about 60 percent of the neurons had different activity patterns depending on the context (Short versus Long). To make sense of these signals, the researchers analyzed the evolution of neural activity across the entire population over time, and found that prior beliefs bias behavioral responses by warping the neural representation of time toward the middle of the expected range.
“We have never seen such a concrete example of how the brain uses prior experience to modify the neural dynamics by which it generates sequences of neural activities, to correct for its own imprecision. This is the unique strength of this paper: bringing together perception, neural dynamics, and Bayesian computation into a coherent framework, supported by both theory and measurements of behavior and neural activities,” says Mate Lengyel, a professor of computational neuroscience at Cambridge University, who was not involved in the study.
Embedded knowledge
Researchers believe that prior experiences change the strength of connections between neurons. The strength of these connections, also known as synapses, determines how neurons act upon one another and constrains the patterns of activity that a network of interconnected neurons can generate. The finding that prior experiences warp the patterns of neural activity provides a window onto how experience alters synaptic connections. “The brain seems to embed prior experiences into synaptic connections so that patterns of brain activity are appropriately biased,” Jazayeri says.
As an independent test of these ideas, the researchers developed a computer model consisting of a network of neurons that could perform the same ready-set-go task. Using techniques borrowed from machine learning, they were able to modify the synaptic connections and create a model that behaved like the animals.
These models are extremely valuable as they provide a substrate for the detailed analysis of the underlying mechanisms, a procedure that is known as “reverse-engineering.” Remarkably, reverse-engineering the model revealed that it solved the task the same way the monkeys’ brain did. The model also had a warped representation of time according to prior experience.
The researchers used the computer model to further dissect the underlying mechanisms using perturbation experiments that are currently impossible to do in the brain. Using this approach, they were able to show that unwarping the neural representations removes the bias in the behavior. This important finding validated the critical role of warping in Bayesian integration of prior knowledge.
The researchers now plan to study how the brain builds up and slowly fine-tunes the synaptic connections that encode prior beliefs as an animal is learning to perform the timing task.
The research was funded by the Center for Sensorimotor Neural Engineering, the Netherlands Scientific Organization, the Marie Sklodowska Curie Reintegration Grant, the National Institutes of Health, the Sloan Foundation, the Klingenstein Foundation, the Simons Foundation, the McKnight Foundation, and the McGovern Institute.
Evelina (Ev) Fedorenko aims to understand how the language system works in the brain. Her lab is unpacking the internal architecture of the brain’s language system and exploring the relationship between language and various cognitive, perceptual, and motor systems. To do this, her lab employs a range of approaches – from brain imaging to computational modeling – and works with a diverse populations, including polyglots and individuals with atypical brains. Language is a quintessential human ability, but the function that language serves has been debated for centuries. Fedorenko argues that language serves is primarily as a tool for communication, contrary to a prominent view that language is essential for thinking.
Ultimately, this cutting-edge work is uncovering the computations and representations that fuel language processing in the brain.
Biography
Ev Fedorenko received her bachelor’s degree from Harvard University in 2002 and her PhD in brain and cognitive sciences from MIT in 2007. In 2014, she joined the faculty at Massachusetts General Hospital and Harvard Medical School, and in 2019 she returned to MIT as an assistant professor in the Department of Brain and Cognitive Sciences.
Fedorenko is currently an associate professor of brain and cognitive sciences and an investigator at the McGovern Institute at MIT.
Honors and Awards
Awards
2023 – Excellence in Undergraduate Teaching, Department of Brain and Cognitive Sciences, MIT
2022 – Outstanding Postdoctoral Mentor, Department of Brain and Cognitive Sciences, MIT
2021 – Excellence in Undergraduate Advising, Department of Brain and Cognitive Sciences, MIT
2020, 2021 – Paul and Lilah Newton Brain Science Award
2020-2023 – Frederick A. (1971) and Carole J. Middleton Professor of Neuroscience, MIT
2018-2020 – Mercator Fellow, University of Potsdam
2014 – 2015 – US Fellow, Kavli Foundation
2009-2011; 2014-2017 – Pathway to Independence Career Development Award, National Institutes of Health
Most neurons have many branching extensions called dendrites that receive input from thousands of other neurons. Dendrites aren’t just passive information-carriers, however. According to a new study from MIT, they appear to play a surprisingly large role in neurons’ ability to translate incoming signals into electrical activity.
Neuroscientists had previously suspected that dendrites might be active only rarely, under specific circumstances, but the MIT team found that dendrites are nearly always active when the main cell body of the neuron is active.
“It seems like dendritic spikes are an intrinsic feature of how neurons in our brain can compute information. They’re not a rare event,” says Lou Beaulieu-Laroche, an MIT graduate student and the lead author of the study. “All the neurons that we looked at had these dendritic spikes, and they had dendritic spikes very frequently.”
The findings suggest that the role of dendrites in the brain’s computational ability is much larger than had previously been thought, says Mark Harnett, who is the Fred and Carole Middleton Career Development Assistant Professor of Brain and Cognitive Sciences, a member of the McGovern Institute for Brain Research, and the senior author of the paper.
“It’s really quite different than how the field had been thinking about this,” he says. “This is evidence that dendrites are actively engaged in producing and shaping the outputs of neurons.”
Graduate student Enrique Toloza and technical associate Norma Brown are also authors of the paper, which appears in Neuron on June 6.
“A far-flung antenna”
Dendrites receive input from many other neurons and carry those signals to the cell body, also called the soma. If stimulated enough, a neuron fires an action potential — an electrical impulse that spreads to other neurons. Large networks of these neurons communicate with each other to perform complex cognitive tasks such as producing speech.
Through imaging and electrical recording, neuroscientists have learned a great deal about the anatomical and functional differences between different types of neurons in the brain’s cortex, but little is known about how they incorporate dendritic inputs and decide whether to fire an action potential. Dendrites give neurons their characteristic branching tree shape, and the size of the “dendritic arbor” far exceeds the size of the soma.
“It’s an enormous, far-flung antenna that’s listening to thousands of synaptic inputs distributed in space along that branching structure from all the other neurons in the network,” Harnett says.
Some neuroscientists have hypothesized that dendrites are active only rarely, while others thought it possible that dendrites play a more central role in neurons’ overall activity. Until now, it has been difficult to test which of these ideas is more accurate, Harnett says.
To explore dendrites’ role in neural computation, the MIT team used calcium imaging to simultaneously measure activity in both the soma and dendrites of individual neurons in the visual cortex of the brain. Calcium flows into neurons when they are electrically active, so this measurement allowed the researchers to compare the activity of dendrites and soma of the same neuron. The imaging was done while mice performed simple tasks such as running on a treadmill or watching a movie.
Unexpectedly, the researchers found that activity in the soma was highly correlated with dendrite activity. That is, when the soma of a particular neuron was active, the dendrites of that neuron were also active most of the time. This was particularly surprising because the animals weren’t performing any kind of cognitively demanding task, Harnett says.
“They weren’t engaged in a task where they had to really perform and call upon cognitive processes or memory. This is pretty simple, low-level processing, and already we have evidence for active dendritic processing in almost all the neurons,” he says. “We were really surprised to see that.”
Evolving patterns
The researchers don’t yet know precisely how dendritic input contributes to neurons’ overall activity, or what exactly the neurons they studied are doing.
“We know that some of those neurons respond to some visual stimuli, but we don’t necessarily know what those individual neurons are representing. All we can say is that whatever the neuron is representing, the dendrites are actively participating in that,” Beaulieu-Laroche says.
While more work remains to determine exactly how the activity in the dendrites and the soma are linked, “it is these tour-de-force in vivo measurements that are critical for explicitly testing hypotheses regarding electrical signaling in neurons,” says Marla Feller, a professor of neurobiology at the University of California at Berkeley, who was not involved in the research.
The MIT team now plans to investigate how dendritic activity contributes to overall neuronal function by manipulating dendrite activity and then measuring how it affects the activity of the cell body, Harnett says. They also plan to study whether the activity patterns they observed evolve as animals learn a new task.
“One hypothesis is that dendritic activity will actually sharpen up for representing features of a task you taught the animals, and all the other dendritic activity, and all the other somatic activity, is going to get dampened down in the rest of the cortical cells that are not involved,” Harnett says.
The research was funded by the Natural Sciences and Engineering Research Council of Canada and the U.S. National Institutes of Health.