Language is a defining feature of humanity, and for centuries, philosophers and scientists have contemplated its true purpose. We use language to share information and exchange ideas—but is it more than that? Do we use language not just to communicate, but to think?
In the June 19, 2024, issue of the journal Nature, McGovern Institute neuroscientist Evelina Fedorenko and colleagues argue that we do not. Language, they say, is primarily a tool for communication.
Fedorenko acknowledges that there is an intuitive link between language and thought. Many people experience an inner voice that seems to narrate their own thoughts. And it’s not unreasonable to expect that well-spoken, articulate individuals are also clear thinkers. But as compelling as these associations can be, they are not evidence that we actually use language to think.
“I think there are a few strands of intuition and confusions that have led people to believe very strongly that language is the medium of thought,” she says.
“But when they are pulled apart thread by thread, they don’t really hold up to empirical scrutiny.”
Separating language and thought
For centuries, language’s potential role in facilitating thinking was nearly impossible to evaluate scientifically.
McGovern Investivator Ev Fedorenko in the Martinos Imaging Center at MIT. Photo: Caitlin Cunningham
But neuroscientists and cognitive scientists now have tools that enable a more rigorous consideration of the idea. Evidence from both fields, which Fedorenko, MIT cognitive scientist and linguist Edward Gibson, and University of California Berkeley cognitive scientist Steven Piantadosi review in their Nature Perspective, supports the idea that language is a tool for communication, not for thought.
“What we’ve learned by using methods that actually tell us about the engagement of the linguistic processing mechanisms is that those mechanisms are not really engaged when we think,” Fedorenko says. Also, she adds, “you can take those mechanisms away, and it seems that thinking can go on just fine.”
Over the past 20 years, Fedorenko and other neuroscientists have advanced our understanding of what happens in the brain as it generates and understands language. Now, using functional MRI to find parts of the brain that are specifically engaged when someone reads or listens to sentences or passages, they can reliably identify an individual’s language-processing network. Then they can monitor those brain regions while the person performs other tasks, from solving a sudoku puzzle to reasoning about other people’s beliefs.
“Your language system is basically silent when you do all sorts of thinking.” – Ev Fedorenko
“Pretty much everything we’ve tested so far, we don’t see any evidence of the engagement of the language mechanisms,” Fedorenko says. “Your language system is basically silent when you do all sorts of thinking.”
That’s consistent with observations from people who have lost the ability to process language due to an injury or stroke. Severely affected patients can be completely unable to process words, yet this does not interfere with their ability to solve math problems, play chess, or plan for future events. “They can do all the things that they could do before their injury. They just can’t take those mental representations and convert them into a format which would allow them to talk about them with others,” Fedorenko says. “If language gives us the core representations that we use for reasoning, then…destroying the language system should lead to problems in thinking as well, and it really doesn’t.”
Conversely, intellectual impairments do not always associate with language impairment; people with intellectual disability disorders or neuropsychiatric disorders that limit their ability to think and reason do not necessarily have problems with basic linguistic functions. Just as language does not appear to be necessary for thought, Fedorenko and colleagues conclude that it is also not sufficient to produce clear thinking.
Language optimization
In addition to arguing that language is unlikely to be used for thinking, the scientists considered its suitability as a communication tool, drawing on findings from linguistic analyses. Analyses across dozens of diverse languages, both spoken and signed, have found recurring features that make them easy to produce and understand. “It turns out that pretty much any property you look at, you can find evidence that languages are optimized in a way that makes information transfer as efficient as possible,” Fedorenko says.
That’s not a new idea, but it has held up as linguists analyze larger corpora across more diverse sets of languages, which has become possible in recent years as the field has assembled corpora that are annotated for various linguistic features. Such studies find that across languages, sounds and words tend to be pieced together in ways that minimize effort for the language producer without muddling the message. For example, commonly used words tend to be short, while words whose meanings depend on one another tend to cluster close together in sentences. Likewise, linguists have noted features that help languages convey meaning despite potential “signal distortions,” whether due to attention lapses or ambient noise.
“All of these features seem to suggest that the forms of languages are optimized to make communication easier,” Fedorenko says, pointing out that such features would be irrelevant if language was primarily a tool for internal thought.
“Given that languages have all these properties, it’s likely that we use language for communication,” she says. She and her coauthors conclude that as a powerful tool for transmitting knowledge, language reflects the sophistication of human cognition—but does not give rise to it.
One of the hallmarks of humanity is language, but now, powerful new artificial intelligence tools also compose poetry, write songs, and have extensive conversations with human users. Tools like ChatGPT and Gemini are widely available at the tap of a button — but just how smart are these AIs?
A new multidisciplinary research effort co-led by Anna (Anya) Ivanova, assistant professor in the School of Psychology at Georgia Tech, alongside Kyle Mahowald, an assistant professor in the Department of Linguistics at the University of Texas at Austin, is working to uncover just that.
Their results could lead to innovative AIs that are more similar to the human brain than ever before — and also help neuroscientists and psychologists who are unearthing the secrets of our own minds.
The study, “Dissociating Language and Thought in Large Language Models,” is published this week in the scientific journal Trends in Cognitive Sciences. The work is already making waves in the scientific community: an earlier preprint of the paper, released in January 2023, has already been cited more than 150 times by fellow researchers. The research team has continued to refine the research for this final journal publication.
“ChatGPT became available while we were finalizing the preprint,” explains Ivanova, who conducted the research while a postdoctoral researcher at MIT’s McGovern Institute. “Over the past year, we’ve had an opportunity to update our arguments in light of this newer generation of models, now including ChatGPT.”
Form versus function
The study focuses on large language models (LLMs), which include AIs like ChatGPT. LLMs are text prediction models, and create writing by predicting which word comes next in a sentence — just like how a cell phone or email service like Gmail might suggest what next word you might want to write. However, while this type of language learning is extremely effective at creating coherent sentences, that doesn’t necessarily signify intelligence.
Ivanova’s team argues that formal competence — creating a well-structured, grammatically correct sentence — should be differentiated from functional competence — answering the right question, communicating the correct information, or appropriately communicating. They also found that while LLMs trained on text prediction are often very good at formal skills, they still struggle with functional skills.
“We humans have the tendency to conflate language and thought,” Ivanova says. “I think that’s an important thing to keep in mind as we’re trying to figure out what these models are capable of, because using that ability to be good at language, to be good at formal competence, leads many people to assume that AIs are also good at thinking — even when that’s not the case.
It’s a heuristic that we developed when interacting with other humans over thousands of years of evolution, but now in some respects, that heuristic is broken,” Ivanova explains.
The distinction between formal and functional competence is also vital in rigorously testing an AI’s capabilities, Ivanova adds. Evaluations often don’t distinguish formal and functional competence, making it difficult to assess what factors are determining a model’s success or failure. The need to develop distinct tests is one of the team’s more widely accepted findings, and one that some researchers in the field have already begun to implement.
Creating a modular system
While the human tendency to conflate functional and formal competence may have hindered understanding of LLMs in the past, our human brains could also be the key to unlocking more powerful AIs.
Leveraging the tools of cognitive neuroscience while a postdoctoral associate at Massachusetts Institute of Technology (MIT), Ivanova and her team studied brain activity in neurotypical individuals via fMRI, and used behavioral assessments of individuals with brain damage to test the causal role of brain regions in language and cognition — both conducting new research and drawing on previous studies. The team’s results showed that human brains use different regions for functional and formal competence, further supporting this distinction in AIs.
“Our research shows that in the brain, there is a language processing module and separate modules for reasoning,” Ivanova says. This modularity could also serve as a blueprint for how to develop future AIs.
“Building on insights from human brains — where the language processing system is sharply distinct from the systems that support our ability to think — we argue that the language-thought distinction is conceptually important for thinking about, evaluating, and improving large language models, especially given recent efforts to imbue these models with human-like intelligence,” says Ivanova’s former advisor and study co-author Evelina Fedorenko, a professor of brain and cognitive sciences at MIT and a member of the McGovern Institute for Brain Research.
Developing AIs in the pattern of the human brain could help create more powerful systems — while also helping them dovetail more naturally with human users. “Generally, differences in a mechanism’s internal structure affect behavior,” Ivanova says. “Building a system that has a broad macroscopic organization similar to that of the human brain could help ensure that it might be more aligned with humans down the road.”
In the rapidly developing world of AI, these systems are ripe for experimentation. After the team’s preprint was published, OpenAI announced their intention to add plug-ins to their GPT models.
“That plug-in system is actually very similar to what we suggest,” Ivanova adds. “It takes a modularity approach where the language model can be an interface to another specialized module within a system.”
While the OpenAI plug-in system will include features like booking flights and ordering food, rather than cognitively inspired features, it demonstrates that “the approach has a lot of potential,” Ivanova says.
The future of AI — and what it can tell us about ourselves
While our own brains might be the key to unlocking better, more powerful AIs, these AIs might also help us better understand ourselves. “When researchers try to study the brain and cognition, it’s often useful to have some smaller system where you can actually go in and poke around and see what’s going on before you get to the immense complexity,” Ivanova explains.
However, since human language is unique, model or animal systems are more difficult to relate. That’s where LLMs come in.
“There are lots of surprising similarities between how one would approach the study of the brain and the study of an artificial neural network” like a large language model, she adds. “They are both information processing systems that have biological or artificial neurons to perform computations.”
In many ways, the human brain is still a black box, but openly available AIs offer a unique opportunity to see the synthetic system’s inner workings and modify variables, and explore these corresponding systems like never before.
“It’s a really wonderful model that we have a lot of control over,” Ivanova says. “Neural networks — they are amazing.”
Along with Anna (Anya) Ivanova, Kyle Mahowald, and Evelina Fedorenko, the research team also includes Idan Blank (University of California, Los Angeles), as well as Nancy Kanwisher and Joshua Tenenbaum (Massachusetts Institute of Technology).
A new study of people who speak many languages has found that there is something special about how the brain processes their native language.
In the brains of these polyglots — people who speak five or more languages — the same language regions light up when they listen to any of the languages that they speak. In general, this network responds more strongly to languages in which the speaker is more proficient, with one notable exception: the speaker’s native language. When listening to one’s native language, language network activity drops off significantly.
The findings suggest there is something unique about the first language one acquires, which allows the brain to process it with minimal effort, the researchers say.
“Something makes it a little bit easier to process — maybe it’s that you’ve spent more time using that language — and you get a dip in activity for the native language compared to other languages that you speak proficiently,” says Evelina Fedorenko, an associate professor of neuroscience at MIT, a member of MIT’s McGovern Institute for Brain Research, and the senior author of the study.
Saima Malik-Moraleda, a graduate student in the Speech and Hearing Bioscience and Technology Program at Harvard University, and Olessia Jouravlev, a former MIT postdoc who is now an associate professor at Carleton University, are the lead authors of the paper, which appears today in the journal Cerebral Cortex.
Many languages, one network
McGovern Investivator Ev Fedorenko in the Martinos Imaging Center at MIT. Photo: Caitlin Cunningham
The brain’s language processing network, located primarily in the left hemisphere, includes regions in the frontal and temporal lobes. In a 2021 study, Fedorenko’s lab found that in the brains of polyglots, the language network was less active when listening to their native language than the language networks of people who speak only one language.
In the new study, the researchers wanted to expand on that finding and explore what happens in the brains of polyglots as they listen to languages in which they have varying levels of proficiency. Studying polyglots can help researchers learn more about the functions of the language network, and how languages learned later in life might be represented differently than a native language or languages.
“With polyglots, you can do all of the comparisons within one person. You have languages that vary along a continuum, and you can try to see how the brain modulates responses as a function of proficiency,” Fedorenko says.
For the study, the researchers recruited 34 polyglots, each of whom had at least some degree of proficiency in five or more languages but were not bilingual or multilingual from infancy. Sixteen of the participants spoke 10 or more languages, including one who spoke 54 languages with at least some proficiency.
Each participant was scanned with functional magnetic resonance imaging (fMRI) as they listened to passages read in eight different languages. These included their native language, a language they were highly proficient in, a language they were moderately proficient in, and a language in which they described themselves as having low proficiency.
They were also scanned while listening to four languages they didn’t speak at all. Two of these were languages from the same family (such as Romance languages) as a language they could speak, and two were languages completely unrelated to any languages they spoke.
The passages used for the study came from two different sources, which the researchers had previously developed for other language studies. One was a set of Bible stories recorded in many different languages, and the other consisted of passages from “Alice in Wonderland” translated into many languages.
Brain scans revealed that the language network lit up the most when participants listened to languages in which they were the most proficient. However, that did not hold true for the participants’ native languages, which activated the language network much less than non-native languages in which they had similar proficiency. This suggests that people are so proficient in their native language that the language network doesn’t need to work very hard to interpret it.
“As you increase proficiency, you can engage linguistic computations to a greater extent, so you get these progressively stronger responses. But then if you compare a really high-proficiency language and a native language, it may be that the native language is just a little bit easier, possibly because you’ve had more experience with it,” Fedorenko says.
Brain engagement
The researchers saw a similar phenomenon when polyglots listened to languages that they don’t speak: Their language network was more engaged when listening to languages related to a language that they could understand, than compared to listening to completely unfamiliar languages.
“Here we’re getting a hint that the response in the language network scales up with how much you understand from the input,” Malik-Moraleda says. “We didn’t quantify the level of understanding here, but in the future we’re planning to evaluate how much people are truly understanding the passages that they’re listening to, and then see how that relates to the activation.”
The researchers also found that a brain network known as the multiple demand network, which turns on whenever the brain is performing a cognitively demanding task, also becomes activated when listening to languages other than one’s native language.
“What we’re seeing here is that the language regions are engaged when we process all these languages, and then there’s this other network that comes in for non-native languages to help you out because it’s a harder task,” Malik-Moraleda says.
In this study, most of the polyglots began studying their non-native languages as teenagers or adults, but in future work, the researchers hope to study people who learned multiple languages from a very young age. They also plan to study people who learned one language from infancy but moved to the United States at a very young age and began speaking English as their dominant language, while becoming less proficient in their native language, to help disentangle the effects of proficiency versus age of acquisition on brain responses.
The research was funded by the McGovern Institute for Brain Research, MIT’s Department of Brain and Cognitive Sciences, and the Simons Center for the Social Brain.
The secret to the success of MIT’s Simons Center for the Social Brain is in the name. With a founding philosophy of “collaboration and community” that has supported scores of scientists across more than a dozen Boston-area research institutions, the SCSB advances research by being inherently social.
SCSB’s mission is “to understand the neural mechanisms underlying social cognition and behavior and to translate this knowledge into better diagnosis and treatment of autism spectrum disorders.” When Director Mriganka Sur founded the center in 2012 in partnership with the Simons Foundation Autism Research Initiative (SFARI) of Jim and Marilyn Simons, he envisioned a different way to achieve urgently needed research progress than the traditional approach of funding isolated projects in individual labs. Sur wanted SCSB’s contribution to go beyond papers, though it has generated about 350 and counting. He sought the creation of a sustained, engaged autism research community at MIT and beyond.
“When you have a really big problem that spans so many issues — a clinical presentation, a gene, and everything in between — you have to grapple with multiple scales of inquiry,” says Sur, the Newton Professor of Neuroscience in MIT’s Department of Brain and Cognitive Sciences (BCS) and The Picower Institute for Learning and Memory. “This cannot be solved by one person or one lab. We need to span multiple labs and multiple ways of thinking. That was our vision.”
In parallel with a rich calendar of public colloquia, lunches, and special events, SCSB catalyzes multiperspective, multiscale research collaborations in two programmatic ways. Targeted projects fund multidisciplinary teams of scientists with complementary expertise to collectively tackle a pressing scientific question. Meanwhile, the center supports postdoctoral Simons Fellows with not one, but two mentors, ensuring a further cross-pollination of ideas and methods.
Complementary collaboration
In 11 years, SCSB has funded nine targeted projects. Each one, by design, involves a deep and multifaceted exploration of a major question with both fundamental importance and clinical relevance. The first project, back in 2013, for example, marshaled three labs spanning BCS, the Department of Biology, and The Whitehead Institute for Biomedical Research to advance understanding of how mutation of the Shank3 gene leads to the pathophysiology of Phelan-McDermid Syndrome by working across scales ranging from individual neural connections to whole neurons to circuits and behavior.
Other past projects have applied similarly integrated, multiscale approaches to topics ranging from how 16p11.2 gene deletion alters the development of brain circuits and cognition to the critical role of the thalamic reticular nucleus in information flow during sleep and wakefulness. Two others produced deep examinations of cognitive functions: how we go from hearing a string of words to understanding a sentence’s intended meaning, and the neural and behavioral correlates of deficits in making predictions about social and sensory stimuli. Yet another project laid the groundwork for developing a new animal model for autism research.
SFARI is especially excited by SCSB’s team science approach, says Kelsey Martin, executive vice president of autism and neuroscience at the Simons Foundation. “I’m delighted by the collaborative spirit of the SCSB,” Martin says. “It’s wonderful to see and learn about the multidisciplinary team-centered collaborations sponsored by the center.”
New projects
In the last year, SCSB has launched three new targeted projects. One team is investigating why many people with autism experience sensory overload and is testing potential interventions to help. The scientists hypothesize that patients experience a deficit in filtering out the mundane stimuli that neurotypical people predict are safe to ignore. Studies suggest the predictive filter relies on relatively low-frequency “alpha/beta” brain rhythms from deep layers of the cortex moderating the higher frequency “gamma” rhythms in superficial layers that process sensory information.
Together, the labs of Charles Nelson, professor of pediatrics at Boston Children’s Hospital (BCH), and BCS faculty members Bob Desimone, the Doris and Don Berkey Professor of Neuroscience at MIT and director of the McGovern Institute, and Earl K. Miller, the Picower Professor, are testing the hypothesis in two different animal models at MIT and in human volunteers at BCH. In the animals they’ll also try out a new real-time feedback system invented in Miller’s lab that can potentially correct the balance of these rhythms in the brain. And in an animal model engineered with a Shank3 mutation, Desimone’s lab will test a gene therapy, too.
“None of us could do all aspects of this project on our own,” says Miller, an investigator in the Picower Institute. “It could only come about because the three of us are working together, using different approaches.”
Right from the start, Desimone says, close collaboration with Nelson’s group at BCH has been essential. To ensure his and Miller’s measurements in the animals and Nelson’s measurements in the humans are as comparable as possible, they have tightly coordinated their research protocols.
“If we hadn’t had this joint grant we would have chosen a completely different, random set of parameters than Chuck, and the results therefore wouldn’t have been comparable. It would be hard to relate them,” says Desimone, who also directs MIT’s McGovern Institute for Brain Research. “This is a project that could not be accomplished by one lab operating in isolation.”
Another targeted project brings together a coalition of seven labs — six based in BCS (professors Evelina Fedorenko, Edward Gibson, Nancy Kanwisher, Roger Levy, Rebecca Saxe, and Joshua Tenenbaum) and one at Dartmouth College (Caroline Robertson) — for a synergistic study of the cognitive, neural, and computational underpinnings of conversational exchanges. The study will integrate the linguistic and non-linguistic aspects of conversational ability in neurotypical adults and children and those with autism.
Fedorenko said the project builds on advances and collaborations from the earlier language Targeted Project she led with Kanwisher.
“Many directions that we started to pursue continue to be active directions in our labs. But most importantly, it was really fun and allowed the PIs [principal investigators] to interact much more than we normally would and to explore exciting interdisciplinary questions,” Fedorenko says. “When Mriganka approached me a few years after the project’s completion asking about a possible new targeted project, I jumped at the opportunity.”
Gibson and Robertson are studying how people align their dialogue, not only in the content and form of their utterances, but using eye contact. Fedorenko and Kanwisher will employ fMRI to discover key components of a conversation network in the cortex. Saxe will examine the development of conversational ability in toddlers using novel MRI techniques. Levy and Tenenbaum will complement these efforts to improve computational models of language processing and conversation.
The newest Targeted Project posits that the immune system can be harnessed to help treat behavioral symptoms of autism. Four labs — three in BCS and one at Harvard Medical School (HMS) — will study mechanisms by which peripheral immune cells can deliver a potentially therapeutic cytokine to the brain. A study by two of the collaborators, MIT associate professor Gloria Choi and HMS associate professor Jun Huh, showed that when IL-17a reaches excitatory neurons in a region of the mouse cortex, it can calm hyperactivity in circuits associated with social and repetitive behavior symptoms. Huh, an immunologist, will examine how IL-17a can get from the periphery to the brain, while Choi will examine how it has its neurological effects. Sur and MIT associate professor Myriam Heiman will conduct studies of cell types that bridge neural circuits with brain circulatory systems.
“It is quite amazing that we have a core of scientists working on very different things coming together to tackle this one common goal,” Choi says. “I really value that.”
Multiple mentors
While SCSB Targeted Projects unify labs around research, the center’s Simons Fellowships unify labs around young researchers, providing not only funding, but a pair of mentors and free-flowing interactions between their labs. Fellows also gain opportunities to inform and inspire their fundamental research by visiting with patients with autism, Sur says.
“The SCSB postdoctoral program serves a critical role in ensuring that a diversity of outstanding scientists are exposed to autism research during their training, providing a pipeline of new talent and creativity for the field,” adds Martin, of the Simons Foundation.
Simons Fellows praise the extra opportunities afforded by additional mentoring. Postdoc Alex Major was a Simons Fellow in Miller’s lab and that of Nancy Kopell, a mathematics professor at Boston University renowned for her modeling of the brain wave phenomena that the Miller lab studies experimentally.
“The dual mentorship structure is a very useful aspect of the fellowship” Major says. “It is both a chance to network with another PI and provides experience in a different neuroscience sub-field.”
Miller says co-mentoring expands the horizons and capabilities of not only the mentees but also the mentors and their labs. “Collaboration is 21st century neuroscience,” Miller says. “Some our studies of the brain have gotten too big and comprehensive to be encapsulated in just one laboratory. Some of these big questions require multiple approaches and multiple techniques.”
Desimone, who recently co-mentored Seng Bum (Michael Yoo) along with BCS and McGovern colleague Mehrdad Jazayeri in a project studying how animals learn from observing others, agrees.
“We hear from postdocs all the time that they wish they had two mentors, just in general to get another point of view,” Desimone says. “This is a really good thing and it’s a way for faculty members to learn about what other faculty members and their postdocs are doing.”
Indeed, the Simons Center model suggests that research can be very successful when it’s collaborative and social.
With help from an artificial language network, MIT neuroscientists have discovered what kind of sentences are most likely to fire up the brain’s key language processing centers.
The new study reveals that sentences that are more complex, either because of unusual grammar or unexpected meaning, generate stronger responses in these language processing centers. Sentences that are very straightforward barely engage these regions, and nonsensical sequences of words don’t do much for them either.
For example, the researchers found this brain network was most active when reading unusual sentences such as “Buy sell signals remains a particular,” taken from a publicly available language dataset called C4. However, it went quiet when reading something very straightforward, such as “We were sitting on the couch.”
“The input has to be language-like enough to engage the system,” says Evelina Fedorenko, Associate Professor of Neuroscience at MIT and a member of MIT’s McGovern Institute for Brain Research. “And then within that space, if things are really easy to process, then you don’t have much of a response. But if things get difficult, or surprising, if there’s an unusual construction or an unusual set of words that you’re maybe not very familiar with, then the network has to work harder.”
Fedorenko is the senior author of the study, which appears today in Nature Human Behavior. MIT graduate student Greta Tuckute is the lead author of the paper.
Processing language
In this study, the researchers focused on language-processing regions found in the left hemisphere of the brain, which includes Broca’s area as well as other parts of the left frontal and temporal lobes of the brain.
“This language network is highly selective to language, but it’s been harder to actually figure out what is going on in these language regions,” Tuckute says. “We wanted to discover what kinds of sentences, what kinds of linguistic input, drive the left hemisphere language network.”
The researchers began by compiling a set of 1,000 sentences taken from a wide variety of sources — fiction, transcriptions of spoken words, web text, and scientific articles, among many others.
Five human participants read each of the sentences while the researchers measured their language network activity using functional magnetic resonance imaging (fMRI). The researchers then fed those same 1,000 sentences into a large language model — a model similar to ChatGPT, which learns to generate and understand language from predicting the next word in huge amounts of text — and measured the activation patterns of the model in response to each sentence.
Once they had all of those data, the researchers trained a mapping model, known as an “encoding model,” which relates the activation patterns seen in the human brain with those observed in the artificial language model. Once trained, the model could predict how the human language network would respond to any new sentence based on how the artificial language network responded to these 1,000 sentences.
The researchers then used the encoding model to identify 500 new sentences that would generate maximal activity in the human brain (the “drive” sentences), as well as sentences that would elicit minimal activity in the brain’s language network (the “suppress” sentences).
In a group of three new human participants, the researchers found these new sentences did indeed drive and suppress brain activity as predicted.
“This ‘closed-loop’ modulation of brain activity during language processing is novel,” Tuckute says. “Our study shows that the model we’re using (that maps between language-model activations and brain responses) is accurate enough to do this. This is the first demonstration of this approach in brain areas implicated in higher-level cognition, such as the language network.”
Linguistic complexity
To figure out what made certain sentences drive activity more than others, the researchers analyzed the sentences based on 11 different linguistic properties, including grammaticality, plausibility, emotional valence (positive or negative), and how easy it is to visualize the sentence content.
For each of those properties, the researchers asked participants from crowd-sourcing platforms to rate the sentences. They also used a computational technique to quantify each sentence’s “surprisal,” or how uncommon it is compared to other sentences.
This analysis revealed that sentences with higher surprisal generate higher responses in the brain. This is consistent with previous studies showing people have more difficulty processing sentences with higher surprisal, the researchers say.
Another linguistic property that correlated with the language network’s responses was linguistic complexity, which is measured by how much a sentence adheres to the rules of English grammar and how plausible it is, meaning how much sense the content makes, apart from the grammar.
Sentences at either end of the spectrum — either extremely simple, or so complex that they make no sense at all — evoked very little activation in the language network. The largest responses came from sentences that make some sense but require work to figure them out, such as “Jiffy Lube of — of therapies, yes,” which came from the Corpus of Contemporary American English dataset.
“We found that the sentences that elicit the highest brain response have a weird grammatical thing and/or a weird meaning,” Fedorenko says. “There’s something slightly unusual about these sentences.”
The researchers now plan to see if they can extend these findings in speakers of languages other than English. They also hope to explore what type of stimuli may activate language processing regions in the brain’s right hemisphere.
The research was funded by an Amazon Fellowship from the Science Hub, an International Doctoral Fellowship from the American Association of University Women, the MIT-IBM Watson AI Lab, the National Institutes of Health, the McGovern Institute, the Simons Center for the Social Brain, and MIT’s Department of Brain and Cognitive Sciences.
Speaking at the “Generative AI: Shaping the Future” symposium on Nov. 28, the kickoff event of MIT’s Generative AI Week, keynote speaker and iRobot co-founder Rodney Brooks warned attendees against uncritically overestimating the capabilities of this emerging technology, which underpins increasingly powerful tools like OpenAI’s ChatGPT and Google’s Bard.
“Hype leads to hubris, and hubris leads to conceit, and conceit leads to failure,” cautioned Brooks, who is also a professor emeritus at MIT, a former director of the Computer Science and Artificial Intelligence Laboratory (CSAIL), and founder of Robust.AI.
“No one technology has ever surpassed everything else,” he added.
The symposium, which drew hundreds of attendees from academia and industry to the Institute’s Kresge Auditorium, was laced with messages of hope about the opportunities generative AI offers for making the world a better place, including through art and creativity, interspersed with cautionary tales about what could go wrong if these AI tools are not developed responsibly.
Generative AI is a term to describe machine-learning models that learn to generate new material that looks like the data they were trained on. These models have exhibited some incredible capabilities, such as the ability to produce human-like creative writing, translate languages, generate functional computer code, or craft realistic images from text prompts.
In her opening remarks to launch the symposium, MIT President Sally Kornbluth highlighted several projects faculty and students have undertaken to use generative AI to make a positive impact in the world. For example, the work of the Axim Collaborative, an online education initiative launched by MIT and Harvard, includes exploring the educational aspects of generative AI to help underserved students.
The Institute also recently announced seed grants for 27 interdisciplinary faculty research projects centered on how AI will transform people’s lives across society.
In hosting Generative AI Week, MIT hopes to not only showcase this type of innovation, but also generate “collaborative collisions” among attendees, Kornbluth said.
Collaboration involving academics, policymakers, and industry will be critical if we are to safely integrate a rapidly evolving technology like generative AI in ways that are humane and help humans solve problems, she told the audience.
“I honestly cannot think of a challenge more closely aligned with MIT’s mission. It is a profound responsibility, but I have every confidence that we can face it, if we face it head on and if we face it as a community,” she said.
While generative AI holds the potential to help solve some of the planet’s most pressing problems, the emergence of these powerful machine learning models has blurred the distinction between science fiction and reality, said CSAIL Director Daniela Rus in her opening remarks. It is no longer a question of whether we can make machines that produce new content, she said, but how we can use these tools to enhance businesses and ensure sustainability.
“Today, we will discuss the possibility of a future where generative AI does not just exist as a technological marvel, but stands as a source of hope and a force for good,” said Rus, who is also the Andrew and Erna Viterbi Professor in the Department of Electrical Engineering and Computer Science.
But before the discussion dove deeply into the capabilities of generative AI, attendees were first asked to ponder their humanity, as MIT Professor Joshua Bennett read an original poem.
Bennett, a professor in the MIT Literature Section and Distinguished Chair of the Humanities, was asked to write a poem about what it means to be human, and drew inspiration from his daughter, who was born three weeks ago.
The poem told of his experiences as a boy watching Star Trekwith his father and touched on the importance of passing traditions down to the next generation.
In his keynote remarks, Brooks set out to unpack some of the deep, scientific questions surrounding generative AI, as well as explore what the technology can tell us about ourselves.
To begin, he sought to dispel some of the mystery swirling around generative AI tools like ChatGPT by explaining the basics of how this large language model works. ChatGPT, for instance, generates text one word at a time by determining what the next word should be in the context of what it has already written. While a human might write a story by thinking about entire phrases, ChatGPT only focuses on the next word, Brooks explained.
ChatGPT 3.5 is built on a machine-learning model that has 175 billion parameters and has been exposed to billions of pages of text on the web during training. (The newest iteration, ChatGPT 4, is even larger.) It learns correlations between words in this massive corpus of text and uses this knowledge to propose what word might come next when given a prompt.
The model has demonstrated some incredible capabilities, such as the ability to write a sonnet about robots in the style of Shakespeare’s famous Sonnet 18. During his talk, Brooks showcased the sonnet he asked ChatGPT to write side-by-side with his own sonnet.
But while researchers still don’t fully understand exactly how these models work, Brooks assured the audience that generative AI’s seemingly incredible capabilities are not magic, and it doesn’t mean these models can do anything.
His biggest fears about generative AI don’t revolve around models that could someday surpass human intelligence. Rather, he is most worried about researchers who may throw away decades of excellent work that was nearing a breakthrough, just to jump on shiny new advancements in generative AI; venture capital firms that blindly swarm toward technologies that can yield the highest margins; or the possibility that a whole generation of engineers will forget about other forms of software and AI.
At the end of the day, those who believe generative AI can solve the world’s problems and those who believe it will only generate new problems have at least one thing in common: Both groups tend to overestimate the technology, he said.
“What is the conceit with generative AI? The conceit is that it is somehow going to lead to artificial general intelligence. By itself, it is not,” Brooks said.
Following Brooks’ presentation, a group of MIT faculty spoke about their work using generative AI and participated in a panel discussion about future advances, important but underexplored research topics, and the challenges of AI regulation and policy.
The panel consisted of Jacob Andreas, an associate professor in the MIT Department of Electrical Engineering and Computer Science (EECS) and a member of CSAIL; Antonio Torralba, the Delta Electronics Professor of EECS and a member of CSAIL; Ev Fedorenko, an associate professor of brain and cognitive sciences and an investigator at the McGovern Institute for Brain Research at MIT; and Armando Solar-Lezama, a Distinguished Professor of Computing and associate director of CSAIL. It was moderated by William T. Freeman, the Thomas and Gerd Perkins Professor of EECS and a member of CSAIL.
The panelists discussed several potential future research directions around generative AI, including the possibility of integrating perceptual systems, drawing on human senses like touch and smell, rather than focusing primarily on language and images. The researchers also spoke about the importance of engaging with policymakers and the public to ensure generative AI tools are produced and deployed responsibly.
“One of the big risks with generative AI today is the risk of digital snake oil. There is a big risk of a lot of products going out that claim to do miraculous things but in the long run could be very harmful,” Solar-Lezama said.
The morning session concluded with an excerpt from the 1925 science fiction novel “Metropolis,” read by senior Joy Ma, a physics and theater arts major, followed by a roundtable discussion on the future of generative AI. The discussion included Joshua Tenenbaum, a professor in the Department of Brain and Cognitive Sciences and a member of CSAIL; Dina Katabi, the Thuan and Nicole Pham Professor in EECS and a principal investigator in CSAIL and the MIT Jameel Clinic; and Max Tegmark, professor of physics; and was moderated by Daniela Rus.
One focus of the discussion was the possibility of developing generative AI models that can go beyond what we can do as humans, such as tools that can sense someone’s emotions by using electromagnetic signals to understand how a person’s breathing and heart rate are changing.
But one key to integrating AI like this into the real world safely is to ensure that we can trust it, Tegmark said. If we know an AI tool will meet the specifications we insist on, then “we no longer have to be afraid of building really powerful systems that go out and do things for us in the world,” he said.
by Maura R. O'Connor | Department of Brain and Cognitive Sciences |
Over a decade ago, the neuroscientist Ev Fedorenko asked 48 English speakers to complete tasks like reading sentences, recalling information, solving math problems, and listening to music. As they did this, she scanned their brains using functional magnetic resonance imaging to see which circuits were activated. If, as linguists have proposed for decades, language is connected to thought in the human brain, then the language processing regions would be activated even during nonlinguistic tasks.
Fedorenko’s experiment, published in 2011 in the Proceedings of the National Academy of Sciences, showed that when it comes to arithmetic, musical processing, general working memory, and other nonlinguistic tasks, language regions of the human brain showed no response. Contrary to what many linguistists have claimed, complex thought and language are separate things. One does not require the other. “We have this highly specialized place in the brain that doesn’t respond to other activities,” says Fedorenko, who is an associate professor at the Department of Brain and Cognitive Sciences (BCS) and the McGovern Institute for Brain Research. “It’s not true that thought critically needs language.”
The design of the experiment, using neuroscience to understand how language works, how it evolved, and its relation to other cognitive functions, is at the heart of Fedorenko’s research. She is part of a unique intellectual triad at MIT’s Department of BCS, along with her colleagues Roger Levy and Ted Gibson. (Gibson and Fedorenko have been married since 2007). Together they have engaged in a years-long collaboration and built a significant body of research focused on some of the biggest questions in linguistics and human cognition. While working in three independent labs — EvLab, TedLab, and the Computational Psycholinguistics Lab — the researchers are motivated by a shared fascination with the human mind and how language works in the brain. “We have a great deal of interaction and collaboration,” says Levy. “It’s a very broadly collaborative, intellectually rich and diverse landscape.”
Using combinations of computational modeling, psycholinguistic experimentation, behavioral data, brain imaging, and large naturalistic language datasets, the researchers also share an answer to a fundamental question: What is the purpose of language? Of all the possible answers to why we have language, perhaps the simplest and most obvious is communication. “Believe it or not,” says Ted Gibson, “that is not the standard answer.”
Gibson first came to MIT in 1993 and joined the faculty of the Linguistics Department in 1997. Recalling the experience today, he describes it as frustrating. The field of linguistics at that time was dominated by the ideas of Noam Chomsky, one of the founders of MIT’s Graduate Program in Linguistics, who has been called the father of modern linguistics. Chomsky’s “nativist” theories of language posited that the purpose of language is the articulation of thought and that language capacity is built-in in advance of any learning. But Gibson, with his training in math and computer science, felt that researchers didn’t satisfyingly test these ideas. He believed that finding the answer to many outstanding questions about language required quantitative research, a departure from standard linguistic methodology. “There’s no reason to rely only on you and your friends, which is how linguistics has worked,” Gibson says. “The data you can get can be much broader if you crowdsource lots of people using experimental methods.” Chomsky’s ascendancy in linguistics presented Gibson with what he saw as a challenge and an opportunity. “I felt like I had to figure it out in detail and see if there was truth in these claims,” he says.
Three decades after he first joined MIT, Gibson believes that the collaborative research at BCS is persuasive and provocative, pointing to new ways of thinking about human culture and cognition. “Now we’re at a stage where it is not just arguments against. We have a lot of positive stuff saying what language is,” he explains. Levy adds: “I would say all three of us are of the view that communication plays a very import role in language learning and processing, but also in the structure of language itself.”
Levy points out that the three researchers completed PhDs in different subjects: Fedorenko in neuroscience, Gibson in computer science, Levy in linguistics. Yet for years before their paths finally converged at MIT, their shared interests in quantitative linguistic research led them to follow each other’s work closely and be influenced by it. The first collaboration between the three was in 2005 and focused on language processing in Russian relative clauses. Around that time, Gibson recalls, Levy was presenting what he describes as “lovely work” that was instrumental in helping him to understand the links between language structure and communication. “Communicative pressures drive the structures,” says Gibson. “Roger was crucial for that. He was the one helping me think about those things a long time ago.”
Levy’s lab is focused on the intersection of artificial intelligence, linguistics, and psychology, using natural language processing tools. “I try to use the tools that are afforded by mathematical and computer science approaches to language to formalize scientific hypotheses about language and the human mind and test those hypotheses,” he says.
Levy points to ongoing research between him and Gibson focused on language comprehension as an example of the benefits of collaboration. “One of the big questions is: When language understanding fails, why does it fail?” Together, the researchers have applied the concept of a “noisy channel,” first developed by the information theorist Claude Shannon in the 1950s, which says that information or messages are corrupted in transmission. “Language understanding unfolds over time, involving an ongoing integration of the past with the present,” says Levy. “Memory itself is an imperfect channel conveying the past from our brain a moment ago to our brain now in order to support successful language understanding.” Indeed, the richness of our linguistic environment, the experience of hundreds of millions of words by adulthood, may create a kind of statistical knowledge guiding our expectations, beliefs, predictions, and interpretations of linguistic meaning. “Statistical knowledge of language actually interacts with the constraints of our memory,” says Levy. “Our experience shapes our memory for language itself.”
All three researchers say they share the belief that by following the evidence, they will eventually discover an even bigger and more complete story about language. “That’s how science goes,” says Fedorenko. “Ted trained me, along with Nancy Kanwisher, and both Ted and Roger are very data-driven. If the data is not giving you the answer you thought, you don’t just keep pushing your story. You think of new hypotheses. Almost everything I have done has been like that.” At times, Fedorenko’s research into parts of the brain’s language system has surprised her and forced her to abandon her hypotheses. “In a certain project I came in with a prior idea that there would be some separation between parts that cared about combinatorics versus words meanings,” she says, “but every little bit of the language system is sensitive to both. At some point, I was like, this is what the data is telling us, and we have to roll with it.”
The researchers’ work pointing to communication as the constitutive purpose of language opens new possibilities for probing and studying non-human language. The standard claim is that human language has a drastically more extensive lexicon than animals, which have no grammar. “But many times, we don’t even know what other species are communicating,” says Gibson. “We say they can’t communicate, but we don’t know. We don’t speak their language.” Fedorenko hopes that more opportunities to make cross-species linguistic comparisons will open up. “Understanding where things are similar and where things diverge would be super useful,” she says.
Meanwhile, the potential applications of language research are far-reaching. One of Levy’s current research projects focuses on how people read and use machine learning algorithms informed by the psychology of eye movements to develop proficiency tests. By tracking the eye movements of people who speak English as a second language while they read texts in English, Levy can predict how good they are at English, an approach that could one day replace the Test of English as a Foreign Language. “It’s an implicit measure of language rather than a much more game-able test,” he says.
The researchers agree that some of the most exciting opportunities in the neuroscience of language lies with large language models that provide new opportunities for asking new questions and making new discoveries. “In the neuroscience of language, the kind of stories that we’ve been able to tell about how the brain does language were limited to verbal, descriptive hypotheses,” says Fedorenko. Computationally implemented models are now amazingly good at language and show some degree of alignment to the brain, she adds. Now, researchers can ask questions such as: what are the actual computations that cells are doing to get meaning from strings of words? “You can now use these models as tools to get insights into how humans might be processing language,” she says. “And you can take the models apart in ways you can’t take apart the brain.”
Tamar Regev, the 2022–2024 Poitras Center Postdoctoral Fellow, has identified a new neural system that may shed light on the auditory hallucinations experienced by patients diagnosed with schizophrenia.
Tamar Regev is the 2022–2024 Poitras Center Postdoctoral Fellow in Ev Fedorenko’s lab at the McGovern Institute. Photo: Steph Stevens
“The system appears integral to prosody processing,”says Regev. “‘Prosody’ can be described as the melody of speech — auditory gestures that we use when we’re speaking to signal linguistic, emotional, and social information.” The prosody processing system Regev has uncovered is distinct from the lower-level auditory speech processing system as well as the higher-level language processing system. Regev aims to understand how the prosody system, along with the speech and language processing systems, may be impaired in neuropsychiatric disorders such as schizophrenia, especially when experienced with auditory hallucinations in the form of speech.
“Knowing which neural systems are affected by schizophrenia can lay the groundwork for future research into interventions that target the mechanisms underlying symptoms such as hallucinations,” says Regev. Passionate about bridging gaps between disciplines, she is collaborating with Ann Shinn, MD, MPH, of McLean Hospital’s Schizophrenia and Bipolar Disorder Research Program.
Regev’s graduate work at the Hebrew University of Jerusalem focused on exploring the auditory system with electroencephalography (EEG), which measures electrical activity in the brain using small electrodes attached to the scalp. She came to MIT to study under Evelina Fedorenko, a world leader in researching the cognitive and neural mechanisms underlying language processing. With Fedorenko she has learned to use functional magnetic resonance imaging (fMRI), which reveals the brain’s functional anatomy by measuring small changes in blood flow that occur with brain activity.
“I hope my research will lead to a better understanding of the neural architectures that underlie these disorders—and eventually help us as a society to better understand and accept special populations.”- Tamar Regev
“EEG has very good temporal resolution but poor spatial resolution, while fMRI provides a map of the brain showing where neural signals are coming from,” says Regev. “With fMRI I can connect my work on the auditory system with that on the language system.”
Regev developed a unique fMRI paradigm to do that. While her human subjects are in the scanner, she is comparing brain responses to speech with expressive prosody versus flat prosody to find the role of the prosody system among the auditory, speech, and language regions. She plans to apply her findings to analyze a rich data set drawn from fMRI studies that Fedorenko and Shinn began a few years ago while investigating the neural basis of auditory hallucinations in patients with schizophrenia and bipolar disorder. Regev is exploring how the neural architecture may differ between control subjects and those with and without auditory hallucinations as well as those with schizophrenia and bipolar disorder.
“This is the first time these questions are being asked using the individual-subject approach developed in the Fedorenko lab,” says Regev. The approach provides superior sensitivity, functional resolution, interpretability, and versatility compared with the group analyses of the past. “I hope my research will lead to a better understanding of the neural architectures that underlie these disorders,” says Regev, “and eventually help us as a society to better understand and accept special populations.”
Artificial intelligence seems to have gotten a lot smarter recently. AI technologies are increasingly integrated into our lives — improving our weather forecasts, finding efficient routes through traffic, personalizing the ads we see and our experiences with social media.
Watercolor image of a robot with a human brain, created using the AI system DALL*E2.
But with the debut of powerful new chatbots like ChatGPT, millions of people have begun interacting with AI tools that seem convincingly human-like. Neuroscientists are taking note — and beginning to dig into what these tools tell us about intelligence and the human brain.
The essence of human intelligence is hard to pin down, let alone engineer. McGovern scientists say there are many kinds of intelligence, and as humans, we call on many different kinds of knowledge and ways of thinking. ChatGPT’s ability to carry on natural conversations with its users has led some to speculate the computer model is sentient, but McGovern neuroscientists insist that the AI technology cannot think for itself.
Still, they say, the field may have reached a turning point.
“I still don’t believe that we can make something that is indistinguishable from a human. I think we’re a long way from that. But for the first time in my life I think there is a small, nonzero chance that it may happen in the next year,” says McGovern founding member Tomaso Poggio, who has studied both human intelligence and machine learning for more than 40 years.
Different sort of intelligence
Developed by the company OpenAI, ChatGPT is an example of a deep neural network, a type of machine learning system that has made its way into virtually every aspect of science and technology. These models learn to perform various tasks by identifying patterns in large datasets. ChatGPT works by scouring texts and detecting and replicating the ways language is used. Drawing on language patterns it finds across the internet, ChatGPT can design you a meal plan, teach you about rocket science, or write a high school-level essay about Mark Twain. With all of the internet as a training tool, models like this have gotten so good at what they do, they can seem all-knowing.
“Engineers have been inventing some of these forms of intelligence since the beginning of the computers. ChatGPT is one. But it is very far from human intelligence.” – Tomaso Poggio
Nonetheless, language models have a restricted skill set. Play with ChatGPT long enough and it will surely give you some wrong information, even if its fluency makes its words deceptively convincing. “These models don’t know about the world, they don’t know about other people’s mental states, they don’t know how things are beyond whatever they can gather from how words go together,” says Postdoctoral Associate Anna Ivanova, who works with McGovern Investigators Evelina Fedorenko and Nancy Kanwisher as well as Jacob Andreas in MIT’s Computer Science and Artificial Intelligence Laboratory.
Such a model, the researchers say, cannot replicate the complex information processing that happens in the human brain. That doesn’t mean language models can’t be intelligent — but theirs is a different sort of intelligence than our own. “I think that there is an infinite number of different forms of intelligence,” says Poggio. “Engineers have been inventing some of these forms of intelligence since the beginning of the computers. ChatGPT is one. But it is very far from human intelligence.”
Under the hood
Just as there are many forms of intelligence, there are also many types of deep learning models — and McGovern researchers are studying the internals of these models to better understand the human brain.
A watercolor painting of a robot generated by DALL*E2.
“These AI models are, in a way, computational hypotheses for what the brain is doing,” Kanwisher says. “Up until a few years ago, we didn’t really have complete computational models of what might be going on in language processing or vision. Once you have a way of generating actual precise models and testing them against real data, you’re kind of off and running in a way that we weren’t ten years ago.”
Artificial neural networks echo the design of the brain in that they are made of densely interconnected networks of simple units that organize themselves — but Poggio says it’s not yet entirely clear how they work.
No one expects that brains and machines will work in exactly the same ways, though some types of deep learning models are more humanlike in their internals than others. For example, a computer vision model developed by McGovern Investigator James DiCarlo responds to images in ways that closely parallel the activity in the visual cortex of animals who are seeing the same thing. DiCarlo’s team can even use their model’s predictions to create an image that will activate specific neurons in an animal’s brain.
“We shouldn’t just automatically assume that if we trained a deep network on a task, that it’s going to look like the brain.” – Ila Fiete
Still, there is reason to be cautious in interpreting what artificial neural networks tell us about biology. “We shouldn’t just automatically assume that if we trained a deep network on a task, that it’s going to look like the brain,” says McGovern Associate Investigator Ila Fiete. Fiete acknowledges that it’s tempting to think of neural networks as models of the brain itself due to their architectural similarities — but she says so far, that idea remains largely untested.
McGovern Institute Associate Investigator Ila Fiete builds theoretical models of the brain. Photo: Caitlin Cunningham
She and her colleagues recently experimented with neural networks that estimate an object’s position in space by integrating information about its changing velocity.
In the brain, specialized neurons known as grid cells carry out this calculation, keeping us aware of where we are as we move through the world. Other researchers had reported that not only can neural networks do this successfully, those that do include components that behave remarkably like grid cells. They had argued that the need to do this kind of path integration must be the reason our brains have grid cells — but Fiete’s team found that artificial networks don’t need to mimic the brain to accomplish this brain-like task. They found that many neural networks can solve the same problem without grid cell-like elements.
One way investigators might generate deep learning models that do work like the brain is to give them a problem that is so complex that there is only one way of solving it, Fiete says.
Language, she acknowledges, might be that complex.
“This is clearly an example of a super-rich task,” she says. “I think on that front, there is a hope that they’re solving such an incredibly difficult task that maybe there is a sense in which they mirror the brain.”
Language parallels
In Fedorenko’s lab, where researchers are focused on identifying and understanding the brain’s language processing circuitry, they have found that some language models do, in fact, mimic certain aspects of human language processing. Many of the most effective models are trained to do a single task: make predictions about word use. That’s what your phone is doing when it suggests words for your text message as you type. Models that are good at this, it turns out, can apply this skill to carrying on conversations, composing essays, and using language in other useful ways. Neuroscientists have found evidence that humans, too, rely on word prediction as a part of language processing.
Fedorenko and her team compared the activity of language models to the brain activity of people as they read or listened to words, sentences, and stories, and found that some models were a better match to human neural responses than others. “The models that do better on this relatively unsophisticated task — just guess what comes next — also do better at capturing human neural responses,” Fedorenko says.
A watercolor painting of a language model, generated by DALL*E2.
It’s a compelling parallel, suggesting computational models and the human brain may have arrived at a similar solution to a problem, even in the face of the biological constraints that have shaped the latter. For Fedorenko and her team, it’s sparked new ideas that they will explore, in part, by modifying existing language models — possibly to more closely mimic the brain.
With so much still unknown about how both human and artificial neural networks learn, Fedorenko says it’s hard to predict what it will take to make language models work and behave more like the human brain. One possibility they are exploring is training a model in a way that more closely mirrors the way children learn language early in life.
Another question, she says, is whether language models might behave more like humans if they had a more limited recall of their own conversations. “All of the state-of-the-art language models keep track of really, really long linguistic contexts. Humans don’t do that,” she says.
Chatbots can retain long strings of dialogue, using those words to tailor their responses as a conversation progresses, she explains. Humans, on the other hand, must cope with a more limited memory. While we can keep track of information as it is conveyed, we only store a string of about eight words as we listen or read. “We get linguistic input, we crunch it up, we extract some kind of meaning representation, presumably in some more abstract format, and then we discard the exact linguistic stream because we don’t need it anymore,” Fedorenko explains.
Language models aren’t able to fill in gaps in conversation with their own knowledge and awareness in the same way a person can, Ivanova adds. “That’s why so far they have to keep track of every single input word,” she says. “If we want a model that models specifically the [human] language network, we don’t need to have this large context window. It would be very cool to train those models on those short windows of context and see if it’s more similar to the language network.”
Multimodal intelligence
Despite these parallels, Fedorenko’s lab has also shown that there are plenty of things language circuits do not do. The brain calls on other circuits to solve math problems, write computer code, and carry out myriad other cognitive processes. Their work makes it clear that in the brain, language and thought are not the same.
That’s borne out by what cognitive neuroscientists like Kanwisher have learned about the functional organization of the human brain, where circuit components are dedicated to surprisingly specific tasks, from language processing to face recognition.
“The upshot of cognitive neuroscience over the last 25 years is that the human brain really has quite a degree of modular organization,” Kanwisher says. “You can look at the brain and say, ‘what does it tell us about the nature of intelligence?’ Well, intelligence is made up of a whole bunch of things.”
In generating this image from the text prompt, “a watercolor painting of a woman looking in a mirror and seeing a robot,” DALL*E2 incorrectly placed the woman (not the robot) in the mirror, highlighting one of the weaknesses of current deep learning models.
In January, Fedorenko, Kanwisher, Ivanova, and colleagues shared an extensive analysis of the capabilities of large language models. After assessing models’ performance on various language-related tasks, they found that despite their mastery of linguistic rules and patterns, such models don’t do a good job using language in real-world situations. From a neuroscience perspective, that kind of functional competence is distinct from formal language competence, calling on not just language-processing circuits but also parts of the brain that store knowledge of the world, reason, and interpret social interactions.
Language is a powerful tool for understanding the world, they say, but it has limits.
“If you train on language prediction alone, you can learn to mimic certain aspects of thinking,” Ivanova says. “But it’s not enough. You need a multimodal system to carry out truly intelligent behavior.”
The team concluded that while AI language models do a very good job using language, they are incomplete models of human thought. For machines to truly think like humans, Ivanova says, they will need a combination of different neural nets all working together, in the same way different networks in the human brain work together to achieve complex cognitive tasks in the real world.
It remains to be seen whether such models would excel in the tech world, but they could prove valuable for revealing insights into human cognition — perhaps in ways that will inform engineers as they strive to build systems that better replicate human intelligence.
EG (a pseudonym) is an accomplished woman in her early 60s: she is a college graduate and has an advanced professional degree. She has a stellar vocabulary—in the 98th percentile, according to tests—and has mastered a foreign language (Russian) to the point that she sometimes dreams in it.
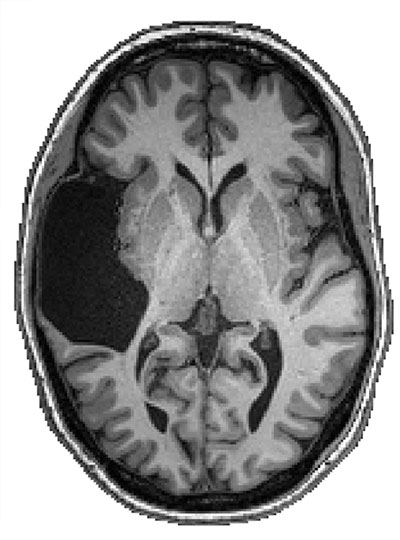
She also has, likely since birth, been missing her left temporal lobe, a part of the brain known to be critical for language.
In 2016, EG contacted McGovern Institute Investigator Evelina Fedorenko, who studies the computations and brain regions that underlie language processing, to see if her team might be interested in including her in their research.
“EG didn’t know about her missing temporal lobe until age 25, when she had a brain scan for an unrelated reason,” says Fedorenko, the Frederick A. (1971) and Carole J. Middleton Career Development Associate Professor of Neuroscience at MIT. “As with many cases of early brain damage, she had no linguistic or cognitive deficits, but brains like hers are invaluable for understanding how cognitive functions reorganize in the tissue that remains.”
“I told her we definitely wanted to study her brain.” – Ev Fedorenko
Previous studies have shown that language processing relies on an interconnected network of frontal and temporal regions in the left hemisphere of the brain. EG’s unique brain presented an opportunity for Fedorenko’s team to explore how language develops in the absence of the temporal part of these core language regions.
Greta Tuckute, a graduate student in the Fedorenko lab, is the first author of the Neuropsychologia study. Photo: Caitlin Cunningham
Their results appeared recently in the journal Neuropsychologia. They found, for the first time, that temporal language regions appear to be critical for the emergence of frontal language regions in the same hemisphere — meaning, without a left temporal lobe, EG’s intact frontal lobe did not develop a capacity for language.
They also reveal much more: EG’s language system resides happily in her right hemisphere. “Our findings provide both visual and statistical proof of the brain’s remarkable plasticity, its ability to reorganize, in the face of extensive early damage,” says Greta Tuckute, a graduate student in the Fedorenko lab and first author of the paper.
In an introduction to the study, EG herself puts the social implications of the findings starkly. “Please do not call my brain abnormal, that creeps me out,” she . “My brain is atypical. If not for accidentally finding these differences, no one would pick me out of a crowd as likely to have these, or any other differences that make me unique.”
How we process language
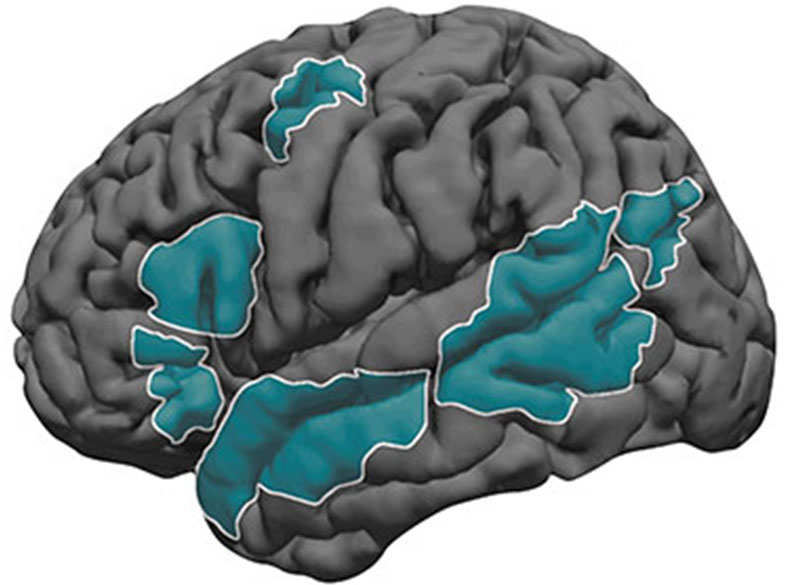
The frontal and temporal lobes are part of the cerebrum, the largest part of the brain. The cerebrum controls many functions, including the five senses, language, working memory, personality, movement, learning, and reasoning. It is divided into two hemispheres, the left and the right, by a deep longitudinal fissure. The two hemispheres communicate via a thick bundle of nerve fibers called the corpus callosum. Each hemisphere comprises four main lobes—frontal, parietal, temporal, and occipital. Core parts of the language network reside in the frontal and temporal lobes.
Core parts of the language network (shown in teal) reside in the left frontal and temporal lobes. Image: Ev Fedorenko
In most individuals, the language system develops in both the right and left hemispheres, with the left side dominant from an early age. The frontal lobe develops slower than the temporal lobe. Together, the interconnected frontal and temporal language areas enable us to understand and produce words, phrases, and sentences.
How, then, did EG, with no left temporal lobe, come to speak, comprehend, and remember verbal information (even a foreign language!) with such proficiency?
Simply put, the right hemisphere took over: “EG has a completely well-functioning neurotypical-like language system in her right hemisphere,” says Tuckute. “It is incredible that a person can use a single hemisphere—and the right hemisphere at that, which in most people is not the dominant hemisphere where language is processed—and be perfectly fine.”
Journey into EG’s brain
In the study, the researchers conducted two scans of EG’s brain using functional magnetic resonance imaging (fMRI), one in 2016 and one in 2019, and had her complete a range of behaviorial tests. fMRI measures the level of blood oxygenation across the brain and can be used to make inferences about where neural activity is taking place. The researchers also scanned the brains of 151 “neurotypical” people. The large number of participants, combined with robust task paradigms and rigorous statistical analyses made it possible to draw conclusions from a single case such as EG.
Magnetic resonance image of EG’s brain showing missing left temporal lobe. Image: Fedorenko Lab
Fedorenko is a staunch advocate of the single case study approach—common in medicine but not currently in neuroscience. “Unusual brains—and unusual individuals more broadly—can provide critical insights into brain organization and function that we simply cannot gain by looking at more typical brains.” Studying individual brains with fMRI, however, requires paradigms that work robustly at the single-brain level. This is not true of most paradigms used in the field, which require averaging many brains together to obtain an effect. Developing individual-level fMRI paradigms for language research has been the focus of Fedorenko’s early work, although the main reason for doing so had nothing to do with studying atypical brains: individual-level analyses are simply better—they are more sensitive and their results are more interpretable and meaningful.
“Looking at high-quality data in an individual participant versus looking at a group-level map is akin to using a high-precision microscope versus looking with a naked myopic eye, when all you see is a blur,” she wrote in an article published in Current Opinion in Behaviorial Sciences in 2021. Having developed and validated such paradigms, though, is now allowing Fedorenko and her group to probe interesting brains.
While in the scanner, each participant performed a task that Fedorenko began developing more than a decade ago. They were presented with a series of words that form real, meaningful sentences, and with a series of “nonwords”—strings of letters that are pronounceable but without meaning. In typical brains, language areas respond more strongly when participants read sentences compared to when they read nonword sequences.
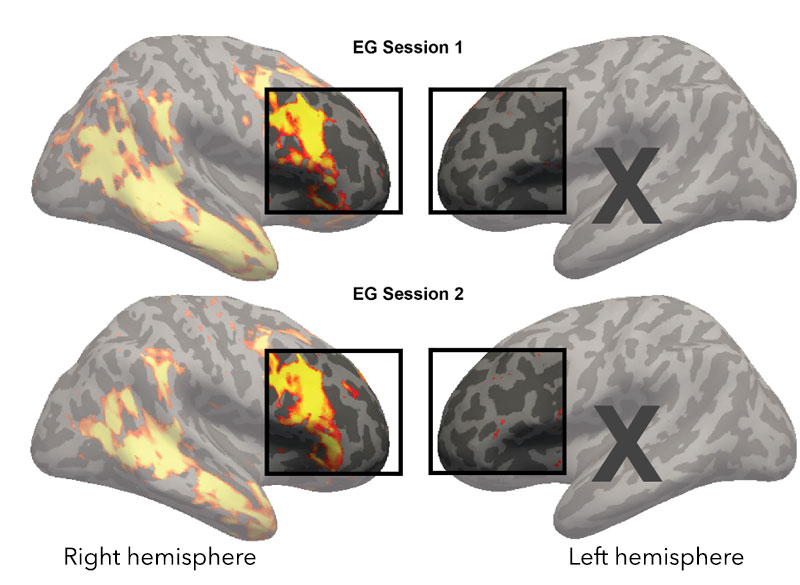
Similarly, in response to the real sentences, the language regions in EG’s right frontal and temporal lobes lit up—they were bursting with activity—while the left frontal lobe regions remained silent. In the neurotypical participants, the language regions in both the left and right frontal and temporal lobes lit up, with the left areas outshining the right.
fMRI showing EG’s language activation on the brain surface. The right frontal lobe shows robust activations, while the left frontal lobe does not have any language responsive areas. Image: Fedorenko lab
“EG showed a very strong response in the right temporal and frontal regions that process language,” says Tuckute. “And if you look at the controls, whose language dominant hemisphere is in the left, EG’s response in her right hemisphere was similar—or even higher—compared to theirs, just on the opposite side.”
Leaving no stone unturned, the researchers next asked whether the lack of language responses in EG’s left frontal lobe might be due to a general lack of response to cognitive tasks rather than just to language. So they conducted a non-language, working-memory task: they had EG and the neurotypical participants perform arithmetic addition problems while in the scanner. In typical brains, this task elicits responses in frontal and parietal areas in both hemisphers.
Not only did regions of EG’s right frontal lobe light up in response to the task, those in her left frontal lobe did, too. “Both EG’s language-dominant (right) hemisphere, and her non-language-dominant (left) hemisphere showed robust responses to this working-memory task ,” says Tuckute. “So, yes, there’s definitely cognitive processing going on there. This selective lack of language responses in EG’s left frontal lobe led us to conclude that, for language, you need the temporal language region to ‘wire up’ the frontal language region.”
Next steps
In science, the answer to one question opens the door to untold more. “In EG, language took over a large chunk of the right frontal and temporal lobes,” says Fedorenko. “So what happens to the functions that in neurotypical individuals generally live in the right hemisphere?”
Many of those, she says, are social functions. The team has already tested EG on social tasks and is currently exploring how those social functions cohabit with the language ones in her right hemisphere. How can they all fit? Do some of the social functions have to migrate to other parts of the brain? They are also working with EG’s family: they have now scanned EG’s three siblings (one of whom is missing most of her right temporal lobe; the other two are neurotypical) and her father (also neurotypical).
The “Interesting Brains Project” website details current projects, findings, and ways to participate.
The project has now grown to include many other individuals with interesting brains, who contacted Fedorenko after some of this work was covered by news outlets. A website for this project can be found here. The project promises to provide unique insights into how our plastic brains reorganize and adapt to various circumstances.