In 1840 a patient named Leborgne was admitted to a hospital near Paris: he was only able repeat the word “Tan.” This loss of speech drew the attention of Paul Broca who, after Leborgne’s death, identified lesions in his frontal lobe in the left hemisphere. These results echoed earlier findings from French neurologist Marc Dax. Now known as “Broca’s area,” the roles of this brain region have been extended to mental functions far beyond speech articulation. So much so, that the underlying functional organization of Broca’s area has become a source of discussion and some confusion.
McGovern Investigator Ev Fedorenko is now calling, in a paper at Trends in Cognitive Sciences, for recognition that Broca’s area consists of functionally distinct, specialized regions, with one sub-region very much dedicated to language processing.
“Broca’s area is one of the first regions you learn about in introductory psychology and neuroscience classes, and arguably laid the foundation for human cognitive neuroscience,” explains Ev Fedorenko, who is also an assistant professor in MIT’s Department of Brain and Cognitive Sciences. “This patch of cortex and its connections with other brain areas and networks provides a microcosm for probing some core questions about the human brain.”
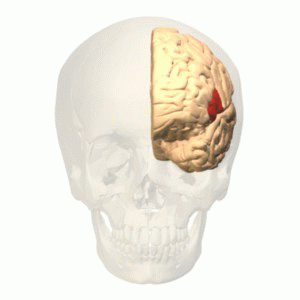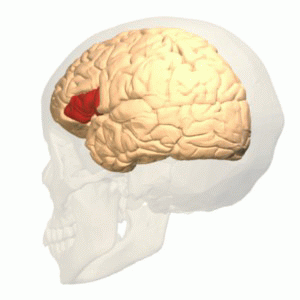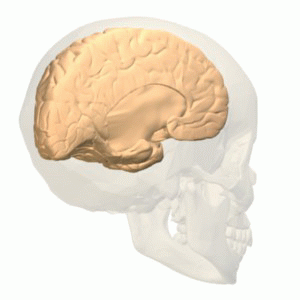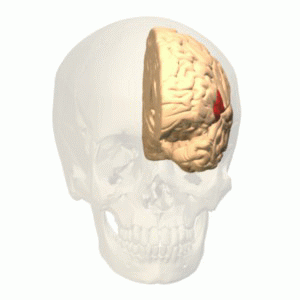
Language is a uniquely human capability, and thus the discovery of Broca’s area immediately captured the attention of researchers.
“Because language is universal across cultures, but unique to the human species, studying Broca’s area and constraining theories of language accordingly promises to provide a window into one of the central abilities that make humans so special,” explains co-author Idan Blank, a former postdoc at the McGovern Institute who is now an assistant professor of psychology at UCLA.
Function over form
Broca’s area is found in the posterior portion of the left inferior frontal gyrus (LIFG). Arguments and theories abound as to its function. Some consider the region as dedicated to language or syntactic processing, others argue that it processes multiple types of inputs, and still others argue it is working at a high level, implementing working memory and cognitive control. Is Broca’s area a highly specialized circuit, dedicated to the human-specific capacity for language and largely independent from the rest high-level cognition, or is it a CPU-like region, overseeing diverse aspects of the mind and orchestrating their operations?
“Patient investigations and neuroimaging studies have now associated Broca’s region with many processes,” explains Blank. “On the one hand, its language-related functions have expanded far beyond articulation, on the other, non-linguistic functions within Broca’s area—fluid intelligence and problem solving, working memory, goal-directed behavior, inhibition, etc.—are fundamental to ‘all of cognition.’”
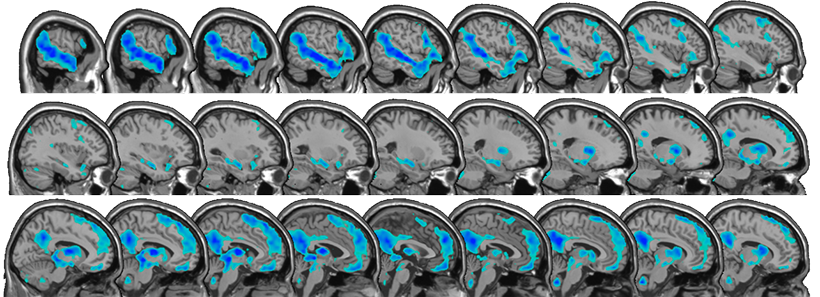
While brain anatomy is a common path to defining subregions in Broca’s area, Fedorenko and Blank argue that instead this approach can muddy the water. In fact, the anatomy of the brain, in terms of cortical folds and visible landmarks that originally stuck out to anatomists, vary from individual to individual in terms of their alignment with the underlying functions of brain regions. While these variations might seem small, they potentially have a huge impact on conclusions about functional regions based on traditional analysis methods. This means that the same bit of anatomy (like, say, the posterior portion of a gyrus) could be doing different things in different brains.
“In both investigations of patients with brain damage and much of brain imaging work, a lot of confusion has stemmed from the use of macroanatomical areas (like the inferior frontal gyrus (IFG)) as ‘units of analysis’,” explains Fedorenko. “When some researchers found IFG activation for a syntactic manipulation, and others for a working memory manipulation, the field jumped to the conclusion that syntactic processing relies on working memory. But these effects might actually be arising in totally distinct parts of the IFG.”
The only way to circumvent this problem is to turn to functional data and aggregate information from functionally defined areas across individuals. Using this approach, across four lines of evidence from the last decade, Fedorenko and Blank came to a clear conclusion: Broca’s area is not a monolithic region with a single function, but contains distinct areas, one dedicated to language processing, and another that supports domain-general functions like working memory.
“We just have to stop referring to macroanatomical brain regions (like gyri and sulci, or their parts) when talking about the functional architecture of the brain,” explains Fedorenko. “I am delighted to see that more and more labs across the world are recognizing the inter-individual variability that characterizes the human brain– this shift is putting us on the right path to making fundamental discoveries about how our brain works.”
Indeed, accounting for distinct functional regions, within Broca’s area and elsewhere, seems essential going forward if we are to truly understand the complexity of the human brain.