This story originally appeared in the Spring 2022 issue of BrainScan.
***
Recent results from cognitive neuroscientist Nancy Kanwisher’s lab have left her pondering the role of music in human evolution. “Music is this big mystery,” she says. “Every human society that’s been studied has music. No other animals have music in the way that humans do. And nobody knows why humans have music at all. This has been a puzzle for centuries.”

Some biologists and anthropologists have reasoned that since there’s no clear evolutionary advantage for humans’ unique ability to create and respond to music, these abilities must have emerged when humans began to repurpose other brain functions. To appreciate song, they’ve proposed, we draw on parts of the brain dedicated to speech and language. It makes sense, Kanwisher says: music and language are both complex, uniquely human ways of communicating. “It’s very sensible to think that there might be common machinery,” she says. “But there isn’t.”
That conclusion is based on her team’s 2015 discovery of neurons in the human brain that respond only to music. They first became clued in to these music-sensitive cells when they asked volunteers to listen to a diverse panel of sounds inside an MRI scanner. Functional brain imaging picked up signals suggesting that some neurons were specialized to detect only music — but the broad map of brain activity generated by an fMRI couldn’t pinpoint those cells.
Singing in the brain
Kanwisher’s team wanted to know more — but neuroscientists who study the human brain can’t always probe its circuitry with the exactitude of their colleagues who study the brains of mice or rats. They can’t insert electrodes into human brains to monitor the neurons they’re interested in. Neurosurgeons, however, sometimes do — and thus, collaborating with neurosurgeons has created unique opportunities for Kanwisher and other McGovern investigators to learn about the human brain.
Kanwisher’s team collaborated with clinicians at Albany Medical Center to work with patients who are undergoing monitoring prior to surgical treatment for epilepsy. Before operating, a neurosurgeon must identify the spot in their patient’s brain that is triggering seizures. This means inserting electrodes into the brain to monitor specific areas over a few days or weeks. The electrodes they implant pinpoint activity far more precisely, both spatially and temporally, than an MRI. And with patients’ permission, researchers like Kanwisher can take advantage of the information they collect.
“The intracranial recording from human brains that’s possible from collaboration with neurosurgeons is extremely precious to us,” Kanwisher says. “All of the research is kind of opportunistic, on whatever the surgeons are doing for clinical reasons. But sometimes we get really lucky and the electrodes are right in an area where we have long-standing scientific questions that those data can answer.”
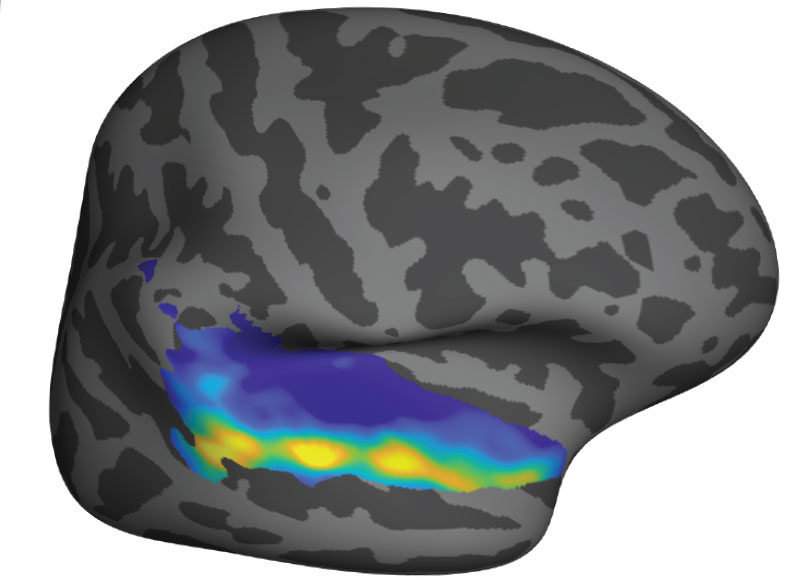
The unexpected discovery of song-specific neurons, led by postdoctoral researcher Sam Norman-Haignere, who is now an assistant professor at the University of Rochester Medical Center, emerged from such a collaboration. The team worked with patients at Albany Medical Center whose presurgical monitoring encompassed the auditory-processing part of the brain that they were curious about. Sure enough, certain electrodes picked up activity only when patients were listening to music. The data indicated that in some of those locations, it didn’t matter what kind of music was playing: the cells fired in response to a range of sounds that included flute solos, heavy metal, and rap. But other locations became active exclusively in response to vocal music. “We did not have that hypothesis at all, Kanwisher says. “It reallytook our breath away,” she says.
When that discovery is considered along with findings from McGovern colleague Ev Fedorenko, who has shown that the brain’s language-processing regions do not respond to music, Kanwisher says it’s now clear that music and language are segregated in the human brain. The origins of our unique appreciation for music, however, remain a mystery.
Clinical advantage
Clinical collaborations are also important to researchers in Ann Graybiel’s lab, who rely largely on model organisms like mice and rats to investigate the fine details of neural circuits. Working with clinicians helps keep them focused on answering questions that matter to patients.
In studying how the brain makes decisions, the Graybiel lab has zeroed in on connections that are vital for making choices that carry both positive and negative consequences. This is the kind of decision-making that you might call on when considering whether to accept a job that pays more but will be more demanding than your current position, for example. In experiments with rats, mice, and monkeys, they’ve identified different neurons dedicated to triggering opposing actions — “approach” or “avoid” — in these complex decision-making tasks. They’ve also found evidence that both age and stress change how the brain deals with these kinds of decisions.
In work led by former Graybiel lab research scientist Ken-ichi Amemori, they have worked with psychiatrist Diego Pizzagalli at McLean Hospital to learn what happens in the human brain when people make these complex decisions.
By monitoring brain activity as people made decisions inside an MRI scanner, the team identified regions that lit up when people chose to “approach” or “avoid.” They also found parallel activity patterns in monkeys that performed the same task, supporting the relevance of animal studies to understanding this circuitry.
In people diagnosed with major depression, however, the brain responded to approach-avoidance conflict somewhat differently. Certain areas were not activated as strongly as they were in people without depression, regardless of whether subjects ultimately chose to “approach” or “avoid.” The team suspects that some of these differences might reflect a stronger tendency toward avoidance, in which potential rewards are less influential for decision-making, while an individual is experiencing major depression.
The brain activity associated with approach-avoidance conflict in humans appears to align with what Graybiel’s team has seen in mice, although clinical imaging cannot reveal nearly as much detail about the involved circuits. Graybiel says that gives her confidence that what they are learning in the lab, where they can manipulate and study neural circuits with precision, is important. “I think there’s no doubt that this is relevant to humans,” she says. “I want to get as far into the mechanisms as possible, because maybe we’ll hit something that’s therapeutically valuable, or maybe we will really get an intuition about how parts of the brain work. I think that will help people.”